Lauren Klien’s “Distant Reading after Moretti” offers a number of points of departure relating to the humanities as a whole, particular disciplines, and the general nature of computation. As an expanded version of our reading “Gender and Cultural Analytics: Finding or Making Stereotypes?”, Klien references Laura Mandell’s revelatory presentation in 2016 at the University of Michigan Library. In the presentation, Mandell expands her analysis of gender and stereotypes to include discussions about Google and various OCR efforts. Her exposures of major biases that completely distort interpretations and studies related to gender, and which occur at all levels of textual research and analysis from the problems of optical character recognition to the misuse of statistical techniques, argue for the importance of carving out an entire subfield or ongoing set of research initiatives dedicated to the critique of computation, along the lines of critical computation studies.
Not all schools of thought within the humanities may advocate for “connect[ing] the project of distant reading to the project of structural critique” or for actively supporting demands for social justice prompted by institutionally sanctioned practices of abuse and dehumanization within academic organizations. But given an academic landscape characterized by humanistic pluralism, scholars such as Klien and Mandell point to the possibilities of building forceful and lasting foundations of rigorous and critical scholarship for academic communities committed to socially engaged and progressive values, foundations which can serve as the leading-edge in the project of exposing and interrogating power.
As one example of how the debates about representativeness, statistical significance, and bias in textual corpora can help methodological critiques in other disciplines, the ways in which historians generalize with broad brush strokes using terms such as “everyone” or “no one” in relation to an entire polity or culture appear less defensible given the construction of albeit problematic digital archives totaling potentially billions of texts and artifacts. Important and crucial skepticism about the archiving and analysis of texts leads to important skepticism about generalizations and abstractions, whether theoretical or empirical, quantitative or qualitative.
In terms of the nature of computation in general, questions that come up include: Is there hidden performativity behind the act of enumeration that gives quantitative analysis the chimera of ideological prestige? To what extent if any do the socially constructed dichotomies between computational work and the traditional work in the humanities (or between the digital and the analog, etc.) reflect the functions class, gender, race, and education within the context of private capital accumulation? Ted Underwood and Richard Jean So underscore the value of experimental, iterative, and error-correcting models and methodologies in computational research. To what extent would a commitment to these approaches address the issues Mandell raises about the problems of text as data regardless of computational techniques?
the gender and race docs were interesting (most interesting) to me this week; both strongly expressing that even distant reading can produce data that can be misread to the advantage of proving a prior theory. what should be undertaken (according to these authors), in the course of conducting this research, is an examination of how certain collections have come to be, and how they may represent falsely distinct collections. using the examples of “white” and “black” race or “male” and “female” gender, we can see that quite a lot is missing from these attributes. not only the affect of identity intersectionalities, but also the definition of what these terms mean in a cultural context from time period “x” to time period “y”.
I thought the gender piece very clearly presented the case for more flexible gender classification and the case against a binary gender mindset and against the conflation gender and sex. the analogy of gender to genre was particularly successful as an aid. Likewise the race piece argued that while it’s possible to find clear commonality among white authors and among black authors, the numbers on closer inspection show the very slight percentage that makes up the difference, and the reason for the separation in texts’ indicators is not quite as clear as it seems when reading the high-level findings of the data.
distance reading, text analysis can provide such a wealth of insights and with the expansion of computational power the possibilities for scholarly discovery are immense. but this area of research going forward will be best served by attention to context, history, and representation in order to provide information that is as holistic and evenly considered as possible.
Earlier this week, I found myself thinking about pre-digital text mining a lot. Of course, the sorts of analysis we use tools like Google Ngram Book Viewer, Voyant, and JSTOR Labs Text Analyzer for have been in existence for far longer than the Internet, albeit in a different forms. Indeed, in my past, I’ve used much less advanced means to “mine” texts: during my junior and senior years of college, I spent quite a bit of time doing just that with Dante’s Divine Comedy, comparing different sections of it to one another, as well as to other texts. I’ve been told about and recommended Ngram and Voyant on many, many occasions in the past, but I’ve never had an excuse to explore them deeper. This project gave me the chance to explore not only those two, but also JSTOR Labs Text Analyzer.
I decided to perform a different experiment with each tool. While Voyant was described as the “easiest” of the tools, at first glance, Ngram drew my attention most due to the fact that it works of a predetermined corpus. This made me think about how reliable it could really be. At best, if one views this corpus as a “standard” of sorts, it could be used to compare multiple studies that used Ngram. However, I find myself wondering if information gained through Ngram could be potentially biased or skewed compared to information gained through other text mining tools that let you establish your own corpus.
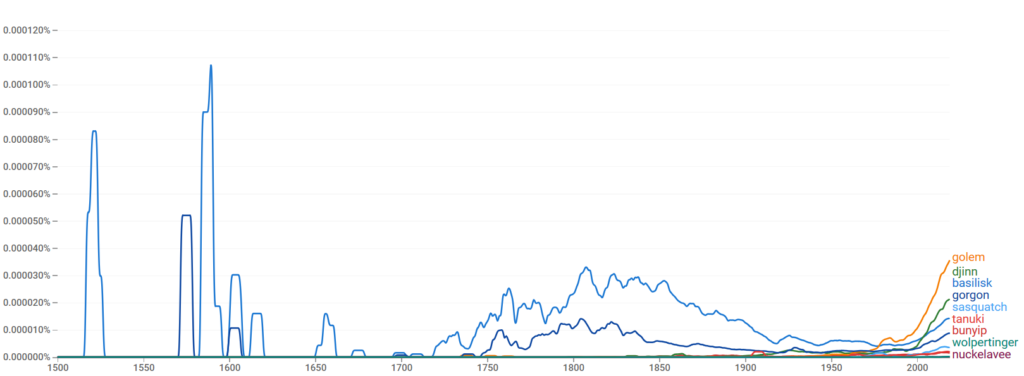
In any case my first experiment wasn’t entirely in line with the project prompt, but I was curious, and I wanted to start somewhere. After reviewing Ngram’s info page, I decided to enter the names of a collection of 9 beings from different folklores and use the longest possible time range available to me (1500-2019). I made sure not to pick anything like “giant” due to the fact that “giant” is a word we use regularly with no attention paid to the associated creature. For consistency’s sake, I also didn’t pick any beings that are explicitly unique, such as gods.
It gets a bit cluttered at points, but I think it presents some interesting results, especially about Ngram’s corpus. It’s immediately clear that the basilisk has the highest peak and overall mentions of any being in this experiment, and even in our time, is only surpassed by two other beings. We also have a pretty clear second place, with the gorgon, who is just below the basilisk, even today. With regards to today though, the golem and djinn went from being fairly obscure to being most and second most popular.
With regards to the former two, the basilisk and gorgon this may indicate a very strong bias in Ngram’s corpus in favor of Cantabrian-Roman (basilisk) and Greek (gorgon) – that is, Western – pre-20th-century mythological texts. Alternatively, it may indicate that writers during those times were using those words more often in figurative language and metaphor (this may be completely arbitrary), or that more editions of myths regarding those creatures came out during those times. With regards to with the latter two, the golem and djinn, respectively from Hebrew and Arabic folklore, have received much more media attention as time’s gone on due to the growth and popularity of the fantasy genre.
The other 5 beings, from most to least frequent in mentions, are respectively from North American, Japanese, Oceanic, Germanic, and Orcadian folklore. The Tanuki has its first uptick in popularity around 1900, or just before the death of Lafcadio Hearn, responsible for some of the first texts on Japanese culture available to a mainstream English-speaking audience. Additionally, while the wolpertinger (Germanic) and nuckelavee (Orcadian) are Western myths, they’re the two least popular, which doesn’t coincide with the apparent bias toward Western mythology. Perhaps it’s specifically a Greco-Roman bias? I would probably have to conduct a more in-depth study.
Moving on, I tried Voyant next. I was excited to upload documents and even experiment with my own writing, but I was surprised to see that I could upload images and even audio files. The first trial I gave it was trying to get it to upload the graph I posted a bit ago, and then a MIDI and an .m4a file I found in my downloads folder. I was saddened to see this:
But I pushed onward and found that Voyant certainly tried to mine the audio file I fed it. Of course, it spat it out as a bunch of garbled text, but I might make a foray into the realm of trying to get practical use out of getting a text miner to mine images and audio in the future. For the time being though, I decided to stick with something more conventional. I tossed it a .txt file with a single haiku on it that I had lying around for a proper test run, and then got to my real experiment. I uploaded a folder of between 40 and 60 Word documents containing poems (certain files contained more than one poem) I wrote since 2013 just to see what would happen, and I got the following lovely word map:
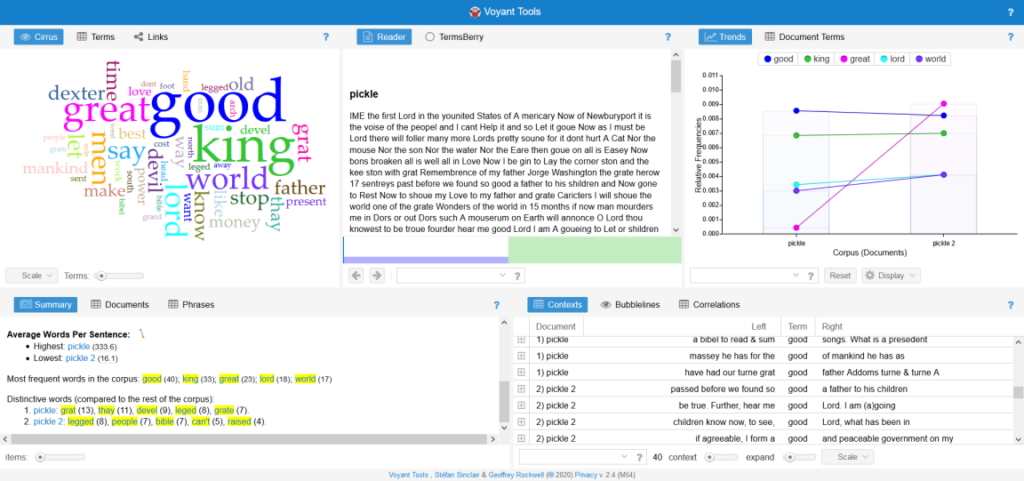
After doing so, I realized there wasn’t a lot of data to glean from this that wasn’t self-indulgent, and at points, personal. Apparently though, I really liked the word “dead” (note: there WAS a poem in there about wordplay regarding the word “dead.” it’s a lot more lighthearted than you’d think). My next, and for the time, final usage of Voyant involved A Pickle for the Knowing Ones by Timothy Dexter: using the “Split Pickle” view of the piece offered by this site, I compared the original text of the piece’s first folio to the site’s “translated” version. For those unaware, Dexter dropped out of school at a young age and was largely illiterate.
Note: “pickle” refers to the original text, whereas “pickle 2” refers to the “translated” version.
Of note, in the untranslated version, the average sentence length is 333.6 words. With this corpus, something of note is that all of the “distinctive words” in the original text are… not really words. The fact that the original has 8 instances of “leged” while the translated version has 8 instances of “legged” is a testament to this.
Finally, I experimented with JSTOR Labs Text Analyzer. Here, I decided to go with an essay I wrote on the overlap between architecture and the philosophy of architecture, traditional narrative, and video game narrative during my senior year of college, and I was pleasantly surprised to the point of being slightly unnerved with the result due to its accuracy.
“Mathematical objects” absolutely includes architecture in the context of the essay.
There was a little less to experiment with on JSTOR, so I mostly left it at that. The number of related texts I was offered was certainly appealing though, and out of the three tools I experimented with, I think this text analyzer would be the one I would use for research, at the very least.
In Richard Jean and Edwin Roland’s essay “Race and Distant Reading” they define distant reading as a process used to “describe the use of quantitative method to study large, digitized corpora of texts”. Basically the practice of this method is to analyze a large number of texts through a digital system, in order to find common textual patterns. The term was coined by literary historian Franco Moretti and has since been debated and critiqued in the field of DH.
The critiques in question have a common thread in the readings we had this week and honestly it’s not something I was exactly shocked to hear about. Biases against race and gender have long been an issue in the literary world. The nuances of both factors are often neglected and not accounted for and distant reading fully showcases that. With distant reading we don’t get the close attention to detail that these components fall under. Lauren F. Klein’s essay “Distant Reading after Moretti” explains that this seems to be a problem of scale- “they require an increased attention to, rather than a passing over, of the subject positions that are too easily (if at times unwittingly) occluded when taking a distant view” and this is where the problem arises. With a “passing over” way of analyzing texts we are left with clichés and stereotypes based off of assumptions.
Not only can these assumptions cause inaccuracies in results but in today’s society the idea of this way of thinking and organizing is just not plausible. Labeling things to fit the criteria of a certain race or gender is near impossible considering the social construct of both is always changing. Gender is no longer just an M/F category and thus should not be viewed as such. In Laura Mandell’s essay she references professor Donna Haraway in “Gender and Cultural Analytics: Finding or Making Stereotype?” and sums up how gender should be viewed in distant reading. One line that really stuck out to me is when she says that gender in writing should be defined as a “category in the making”…as a set of conventions for self-representations that are negotiated and manipulated” Similarly in “Race and Distant Reading”, Jean and Roland state that “the racial ontology of an author is not stable; what it means to be white or black changes over time and place”,they use author Nella Larsen as an example where today most scholars will identify her as black while in the 1920’s she was referred to as mulatta.
Furthermore it goes without saying that race and gender should absolutely not be the only signifier to allude to a writer in analyzing their identity. There are a number of elements that go into forming a person’s identity and such elements should be taken notice of. Klein suggests that exposing these injustices will help make the practice more inclusive, something I really hope takes off because in my opinion the concept of distant reading seems like something that can be of great use in the world of research.
Having just taken part in the HathiTrust digital library workshop I chose to use HathiTrust and their analytical engine to do this text mining assignment. The first step was to find a collection of texts to analyze. Thankfully, HathiTrust has a tab specifically tailored to finding either ready made collections or forming new ones. I chose to use a collection of texts which used the word “detective” in published works prior to 1950. There were only 61 volumes in this particular collection, so it was a good place to start my experiment. It is worth mentioning that should you need to, HathiTrust allows you to make your own collections based on terms you search up. Using this collection I downloaded a TSV file which held all of the volumes in tabs according to the frequency of the word “detective”. HathiTrust’s analytics was located on a different site, where you can upload your TSV file and run algorithms to visualize a topic model of the term used, themes and frequency. Using the InPho Topic Model Explorer I was able to create an interactive topic bubble model. Attached is the link and screenshot of what the map looks like.
The algorithm groups clusters and color codes them automatically according to groups of topics and similar themes. If you follow the link you will see, for example, that the orange clusters are characterized by fictional stories, and mysteries in which the word “detective” is frequently used. If you use your mouse to hover over each bubble you will see these commonalities mentioned quite often. Also, it is easier to discern similar themes and topics if collision detection is turned off. The above image of the topic model is of the model with collision detection turned on. Below is an image of the topic model with collision detection turned off.
Hovering over the cluster with collision detection turned off makes it easier to see what themes the color coded clusters share.
Being curious about the trends of the terms “detective” and “crime” I then utilized HathiTrust’s Bookworm application to further this experiment. The Bookworm search does not use a specific collection, rather it searches HathiTrust’s entire digital library to display a simple double line graph of the usage of terms over time. The end result is a clear visualization of the the trends in term usage over a period of 250 years.
From this graph the most significant take away is the correlation of the uptake in usage of the terms “detective” and “crime” with the rising popularity of detective novels and media from the 1920’s on. Prior to 1920, as is confirmed by the InPho Topic Model, the term “detective” was used in mostly a non-fictional or informational capacity.
A downside to both Bookworm and the InPho Topic Model Explorer is that the texts themselves are not listed. To access the texts used one would either have to record every volume in a collection or look closer into the TSV file itself, as far as I know. Since I attended the workshop finding my way around HathiTrust was not too difficult, however, they are limited by the scope of information available through their digital library. Although partnered with several institutions, including the Grad Center, you may not have much luck mining more obscure terminology. Some terms include those with ethnic connotations or terms not consistent with Western academia, like terms with regional specificity.
As others have mentioned in class, I also generally approach the readings for the week in the order they are presented in our course schedule. And I was excited to be learning more about distance reading: how it’s not necessarily an argument against close reading, seeing similar arguments about acknowledging “data as capta” and that there’s no such thing as an objective distance reading, but there’s room for more complexity and nuance. And of course lots of mentions of Franco Moretti, who originally coined the term.
Then I get to Lauren F. Klein’s “Distance Reading after Moretti.” Moretti has been accused of sexual harassment and assault, the details of which became more broadly known during #MeToo. After briefly acknowledging this, Klein goes on to discuss the ways in which a lack of representation in the field contribute to certain distance reading practitioners reinforcing problematic power structures. Klein says, “And like literary world systems, or ‘the great unread,’ the problems associated with these concepts, like sexism or racism, are also problems of scale, but they require an increased attention to, rather than a passing over, of the subject positions that are too easily (if at times unwittingly) occluded when taking a distant view.”
And then I get to two readings, both written after the allegations, that engage with Moretti and his contributions to the field: Laura Mandell’s “Gender and Cultural Analytics: Finding or Making Stereotypes?” and Richard Jean So and Edwin Roland’s “Race and Distant Reading.” My first thoughts are, can we separate the work from the person who performed it? (I’m not sure, but I’m skeptical.) And then what is the responsibility of a scholar to be aware of such abuses of the people they reference? My first thought was perhaps (being relatively new to the field and unaware of different scholars’ relationships to each other and to the general happenings within DH), maybe they didn’t know. Or maybe this is another issue where the publication date isn’t actually representative of the chronology in which they were written. But both of these articles include Klein’s panel discussion in their works cited. Admittedly both articles are critical of Moretti, but those criticisms are separate from the sexual assault. Do they have to acknowledge this? Does not acknowledging it let Moretti retain his privileged position within the field as being someone against whom discourse on distance reading necessarily has to reference and frequently appear as a starting point from which criticism must begin? I definitely wouldn’t advocate for erasing him from the history of DH and/or distance reading, but I’m not sure just being critical of his work is enough when it’s clear the authors of the latter articles are also familiar with the rape and harassment allegations.
Is this something that only comes with more time (and even if that has been the case, is that the example we should follow)? Is there reputable discourse on the “founding fathers” of the United States that doesn’t address their owning and raping of slaves? (Now that I’ve asked this, I’m fearing the answer may indeed be “yes.”) Medicine certainly still has many skeletons in its closet to contend with, but there has been a movement to rename conditions previously named after Nazi doctors. (I’m not sure this is an example to be followed, but naming medical conditions after people is incredibly problematic and also not very helpful in understanding what a condition really is anyway, so that’s its own can of worms…)
I’m not sure exactly what repercussions Moretti has faced, though I fear little. I found this article from the Standford Politics about him and another professor.
Yesterday I had the pleasure to attend the workshop about Working with HathiTrust data led by Digital Fellow Param Ajmera. In case you missed it, you can find an article about HathiTrust on the Digital Fellows Blog, Tagging the Tower.
HathiTrust is a huge digital library that contains over 17 million volumes, and for this reason it’s particularly good for large-scale text analysis. The advantage of using HathiTrust, as Param showed us, is that you can perform the text analysis on the website of the HathiTrust Research Center – HTRC, a Cloud computing infrastructure that allows us to parse a large amount of text without crashing our computers. And the best part – it’s free and you can create an account with your CUNY login.
Param gave us a live tutorial on how to select the texts we want from HathiTrust and create a collection that we can save and open on HTRC. He created a collection of public papers of American Presidents and used Topic Modeling to find the words that are most commonly used together in these texts. The result was a list of “topics”, groups of words that the algorithm gathered according to how often they appear together. This allowed us to make a comparison between different presidents according to the keywords in their public papers. The experience was very interesting – and with the perfect timing!
The part I enjoyed the most, however, was when Param taught us how to use Bookworm, a tool that creates visualizations of language trends over the entire corpus of HathiTrust. The result is very similar to the Google Ngram Viewer, but Bookworm has one advantage: when you click on a point on the line, you can see a list of the texts where the word appears.
Since topic modeling can take a long time (hours or even days) according to the volume of text you’re working with, I decided to experiment with Bookworm. Here’s my Ngrams:
Being a sci-fi lover, I decided to check the frequency of the words “robot” and “android”. I was initially surprised when I saw that “android”, compared to “robot” had such a low curve. When I checked the texts that were used for the Ngram, I realized that the word “robot” appears in a lot of papers related to engineering, robotics, and information technology, while “android” is a term mostly used in sci-fi. If we look at the curve of “android” alone, we see that the word has a spike in the 1960s. Was it because of Philip Dick? Or Star Trek?
Inspired by the Rocky Horror Picture Show and the TV show “Pose”, I decided to investigate the relative frequency of “transvestite”, “transsexual”, and “transgender” in the HathiTrust corpus. The first two terms sound pretty dated – and rightfully so, while the third one is the most commonly used now. As you can see from the graph, the use of the term “transgender” skyrockets starting in the mid-1980s, beating the other two at the end of the 1990s. Another thing I noticed is that, looking at the texts:
“transvestite” is mostly used to describe a cultural phenomenon (for example in texts about literature, theater, cinema, or fashion)
“transsexual” is used in medical contexts, for example in papers about gender dysphoria
“transgender” is used in a medical context, beating “transsexual” at the end of the 1990s. However, it is also used in and institutional contexts like policies, guidelines, and social justice reforms.
This past Thursday, October 22nd, 2020, I had the opportunity to attend the Working with HathiTrust Data workshop offered by Param Ajmera. HathiTrust Data is most similar to an online historical archive/library on the surface level. This workshop delves deeper into the applications of the HathiTrust digital library as a tool for text analysis and visualization. Having some familiarity on the different uses of historical archives and how they retrieve text through the utilization of key word searches, which the first portion of the workshop demonstrated how to do, I was unsure exactly of what set HathiTrust data apart from traditional historical archives.
Made available through the use of cloud computing infrastructure HathiTrust, like most digital archives, is able to retrieve text in bulk and then analyze said text with the sole purpose of creating visualizations based on topic modeling. Topic modeling, as explained in the workshop, is procedurally described as first creating a workset through input terms and chunking the texts retrieved into documents which are then used to create a visualization based on word usage. It is worth mentioning that HathiTrust uses programs called API’s (Application Programming Interface) used to retrieve and sort texts using your input terms, which are then organized and visualized by a program called Bookworm. A clear example used to demonstrate its use during the workshop was comparing ideological information present in three different President’s speeches. Using the input terms “nationalism” and “internationalism” we were able to see, through the information visualized on a line graph, the ideological prevalence of nationalism and internationalism over the course of 240 years (1760-2000) and the presidencies within that time period, with most of the discernible data being present in the final 120 years (1880-2000). The final part of the workshop provided some scope into the amount of information available on HathiTrust. Although, not partnered with different libraries, millions of titles are still available through partnership with many different academic and research institutions.
I believe that most of the HathiTrust’s utility derives from its streamlined process of predictive word usage and ease of use where Bookworm is coupled with text analysis. This process was described in a non-convoluted, easy to understand way that not only reaffirms the importance of historical review, but also how easily it blends with digital visualization. There is trove of information available through topic modeling and it presents itself as invaluable to the study of history. I believe, however, that this information is only accessible to the wider academic audience through clear, presentable visualization techniques, as texts to be gathered and hits on the usage of certain words can sometimes total in the trillions. HathiTrust’s use of API and Bookworm are two solutions to this problem that I am excited to see adapt with technology.
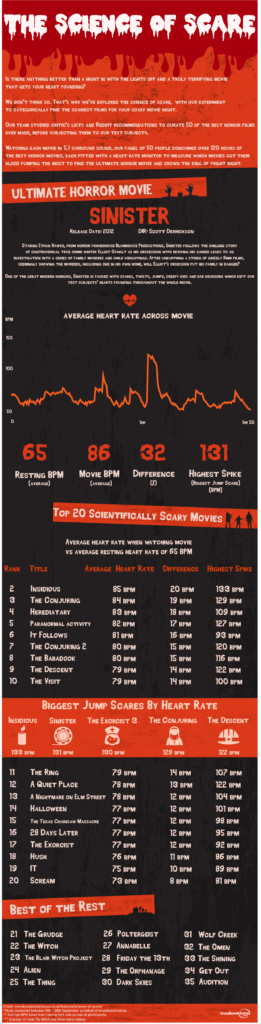
I’m guessing I’m not the only person who’s seen this research study popping up all over their social media. broadbandchoices, a broadband internet, mobile/home phone, and TV provider based in the UK, has conducted a study to determine the scariest horror movie ever made: The Science of Scare. Their team reviewed lists of best horror films from critics and on Reddit, and complied what they believe to be a list of the 50 best horror movies of all time.
Then they found 50 participants and had them all watch of the movies while wearing heart rate monitors to track heart rate spikes and compare average heart rates during the movies with their average resting rates.
The scientific rigor of this study certainly raises a lot of questions. Lists of best movies are incredibly subjective, and they do not provide the number of sources they consulted or provide the specific lists they took their movies from. How much of their final list was determined based on what was easily available to view? Also, they all seem to be predominantly English language movies (The Orphanage is the only one I’m familiar with on that list that was made in Spanish, but did they watch with subtitles or did they watch a dubbed version?). How did they settle on heart rate as the determining factor of what is scary–was it just because heart rate is relatively easy and noninvasive to measure? How did they pick the participants? What are their demographics (a Nerdist writeup says the participants were of different ages, but I’m not seeing anything about that from broadbandchoices)? What was their previous exposure to/feelings about the genre; did they have any pre-existing medical conditions that could have affected their heart rate monitoring? Under what conditions were the films screened–together, individually, at home, consecutively?
What do you all think? Is this just some harmless Halloween fun, or do “studies” like this contribute to a false narrative that data is objective?
For the record, I’ve never even heard of their top movie, and of their list of 35, I’ve seen 18. You?
This week I participated in the workshop “Open Access Explained: Best Practices for Finding Others’ Research and Publicly Sharing Yours” offered by Jill Cirasella, Associate Librarian for Scholarly Communication and Digital Scholarship, and Adriana Palmer, E-Resources Librarian, both at the GC library. The workshop was really informative, and designed to give ‘introductory doses’ for the field of Open Access. After our readings from this week, it was very interesting to then get to learn more about specific tools. The workshop introduced tools for:
Finding scholarship and getting around paywalls
Making you and you work more discoverable on the web
Providing freely accessible full text of your work
Tracking your scholarly impact
Navigating self-archiving commissions for journal articles
The workshop consisted of three sections: the consumption and the production of OA work as well as knowing your rights as a scholar who wants to publish OA work.
The first part was about where to find OA works as a student. The easiest way to look for open access information is through Google Scholar’s Right Side Links: if the work is open access, next to the article on the right side there should be a link that directs you to the OA work. If there is no link Jill emphasized that it is not only a question of accessibility but of discoverability since the tools sometimes can’t find the information/the work, so it’s always good to use the GC version of Google Scholar as it tells you if the GC has access to it. If there is a paywall, the tool Unpaywall (extension for the browser), an open database of free scholarly articles, can provide the peer reviewed manuscript version of an article. There is another browser extension, the Open Access Button, that delivers free and legal articles instantly, and through which (if provided) you can also send an email to the authors requesting access to their work.
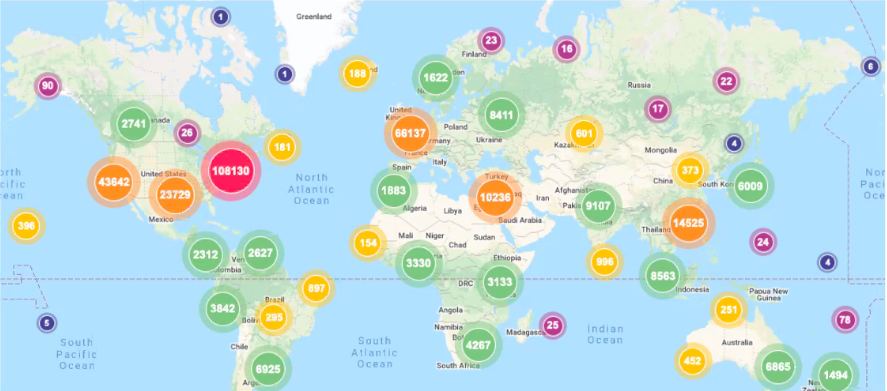
In the second part we talked about considering making our own scholarly work open access. Posting is generally allowed on institutional repositories (like for example CUNY Academic Works), disciplinary repositories (like arXis, SocArxiv, SSRN, etc.), and through Open Access via the publisher (what is considered “gold”or “bronze”OA). We focused on “green” open access: GC Publications & Research on Cuny Academic Works where you can submit your research. CAW provides an author dashboard, a personalized reporting tool for authors with works published on Digital Commons to view current download information for every work you publish as well as global insights into the sources of readership. The data is visualized as maps and statistics. I found this map of GC Publications & Research Readership since 2014 really interesting:
Jill and Amanda also mentioned to use a critical eye when evaluating resources you want to use to self-archive for public access, as some sites have a more commercial impetus for their practices than others, and this can also affect the types of services that may or may not be available to us. They also advised us to create scholarly profiles on for example CUNY Academic Commons, Humanities Commons or Google Scholar, and to follow ourselves to get alerts when we are cited. In the final part “Knowing your Rights” they addressed publisher contracts which I found very informative since I have not yet thought about issues related to that. As with most scholarly journals where you write for free and give it back for free, the reach is limited if the article is behind a paywall through the publisher. In order to share our scholarly work as broadly as we can, we should check publisher contracts, as they have evolved to give copyrights to scholars over the years but they are hard to find. Sherpa Romeo is a database for publisher and journal open access policies from around the world, giving information if you can publish your work online/if the publication allows for open access.
Need help with the Commons?
Email us at [email protected] so we can respond to your questions and requests. Please email from your CUNY email address if possible. Or visit our help site for more information: