This site contains student blog posts and teaching materials related to DHUM 70000: Introduction to the Digital Humanities, which was taught by Prof. Matthew Gold in Fall 2020. We will leave the content of the site available as a record of our class and a resource for others who might be interested in the topics we covered. Please contact us if you have any questions about the material that appears on the site.
I chose to use Voyant as I had played around with it for a classroom exercise earlier in the term (plotting different animal imagery in Aeschylus’ Orestaia). I hadn’t loved the tool but it had confirmed my fundamental close-reading conclusions and added material to them, as well as surprising me by demonstrating sometimes the absence of what I expected to find. The results were pretty rough, as I had to rely on a collected volume in order to use the translation I was teaching for my corpus and clean up the data by narrowing it to the small relevant section that treated the trilogy specifically. I learned enough to make me decide to try it again, however.
This time, I added three texts to the Voyant search: Spanish, French, and English versions of La Monja Alférez; aka the early-seventeenth-century trans memoir of Catalina/Antonio de Erauso. The earliest edition extant remains an eighteenth-century manuscript, but the work was printed throughout the nineteenth centuries in multiple editions.
Again, I was hampered by what was available to download, but, for the English, I settled on Thomas de Quincey’s The Spanish Nun published 1853—a paraphrase or retelling, in which “Catalina” becomes a Shakespearean “Kate.” For the French I chose a late 19th-century French edition, La Nonne Alferez, and for the Spanish the Historia de la Monja Alférez, both of which remain fairly faithful to recent scholarly versions and the early manuscript.
As the Spanish versions of the work show de Erauso shifting from feminine to masculine terms when s/he travel to New Spain, originally I wanted to search for the use of masculine and feminine personal pronouns and adjectival endings in the texts. That proved too complicated for an initial run. But when I discovered that de Quincey had Anglicized de Erauso to fit a very different nationalized gender narrative, I became interested in the extent to which the works identified the author by different names and terms and where those identifiers appeared most respectively.
Results:
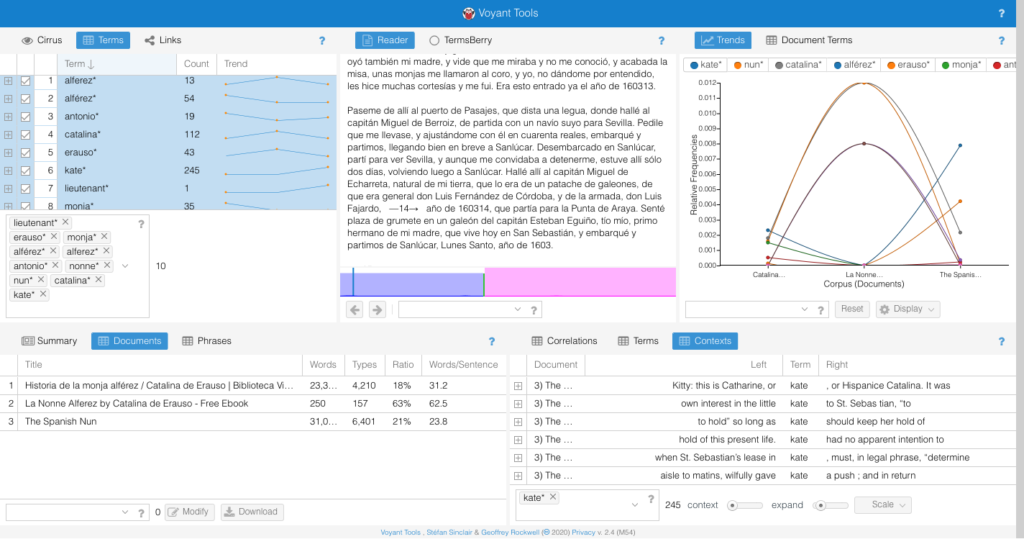
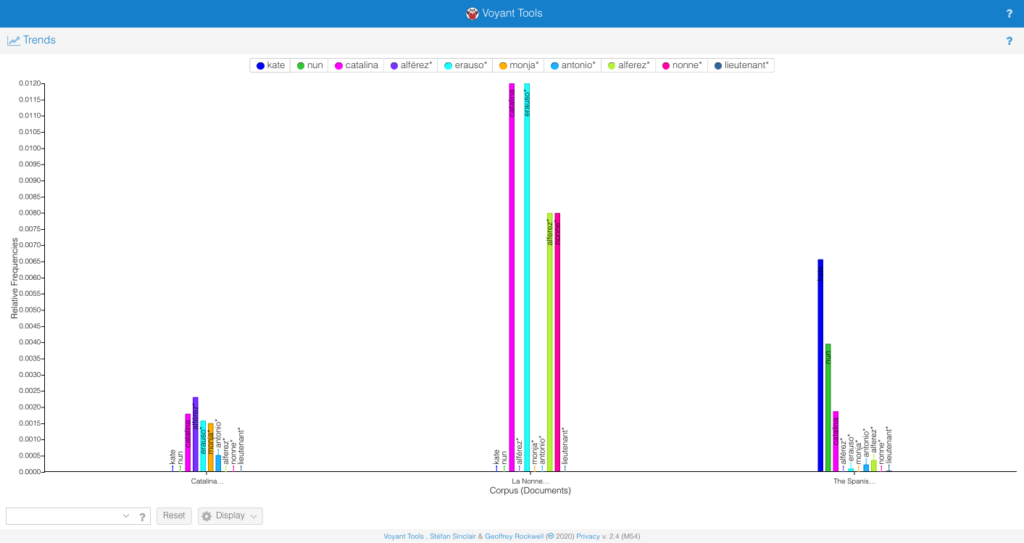
I found the comparison of equivalent terms in each of the works to be the most interesting information.
In the Spanish, “alferez” or “lieutenant” appears more frequently than any proper name or the alternative subject position “monja” i.e. “nun”; it is associated most often with “Catalina” and then with “Erauso.” This suggests an inherent gender clash or ambiguity in the characterization of the protagonist, who appears identified most often with a feminine name linked to a masculine profession.
In the French, both professional identities (“alferez” and “nonne”) are secondary and yet equal to eachother in frequency. Rather, the protagonist is identified by their first and last names and the use of alternate or masculine identifiers other than “alferez” is non-existent. It’s striking that the text uses an archaic term for nun—“nonne”—rather than the more common (and already normative from the time of Diderot’s infamous novel of the same name) “religieuse.” Equally suggestive, the text opts for the Spanish term “alferez” rather than using the more common “lieutenant.” It would be worth exploring the appearance of those terms in other novels of the period to see if this is an attempt to distance de Erauso’s character from the French associations of each term or to emphasize their status as outlandish, foreign, or other.
Lastly, de Quincey’s fairly absurd revision of the narrative not surprisingly uses “Kate” far more than “Catalina” to identify the “heroine”: I use the term intentionally as the English text pairs “Kate” with “nun” and hardly uses any masculine indicators, or even the gender fluid “Erauso” that they maintain throughout their life.
In short, the exercise was useful for identifying the extent to which the French and English translations erased the gender ambiguity of the original Spanish account, making it that much harder to recognize La Monja Alférez as an important early modern instance of a trans text.
This was the last class I’ll ever have to take. After four years of undergrad, two years in my master’s program, and two-and-a-half years into my PhD program, this was the last class I needed to complete my coursework. I feel so lucky to have chosen a class that truly centered students’ learning experiences, and even more lucky to be in a learning community that established a class culture early on of collaboration, enthusiastic inquiry, and vulnerability that made our Wednesday classes something I looked forward to each week.
My plans for my final project changed so much over the semester because I was excited and inspired by so much of the syllabus, but I’m glad I was ultimately able to make the practical decision on an idea that is relevant to the field, my current fellowship, and has already opened up new opportunities for interdisciplinary collaboration. Mapping Our Humanities, my digital project at the intersection of sociological research and public humanities, will allow me to use my expertise as a social scientist to work with political science and humanities activist-scholars to drive change. I’m finalizing the Human Subjects protocol over break and moving forward with the domain and social media plans so that me and my collaborators can hit the ground running Spring semester.
After submitting the proposal, I’ve already identified things I want to change. I’ve been sitting with the tensions of “mapping” discussed in this class–the ways it can reflect or problematize colonial thought, and the importance of intentionality and reflexivity. I’ve been struggling to commit to the name and whether developing pieces that explore these tensions are more helpful than a new name for the project. Similarly with the survey’s use of machine learning, I want to be mindful of the “broken world thinking” embedded in academic methods and structure, but not to the point where I am immobile and too scared to produce anything for fear of imperfection. I feel a little stuck in this tension, but I am thankful for the discourse this class provided because it inspired dimensions of thoughtfulness I could not have explored on my own.
I’m also looking back and finding ways the social science research questions and humanities questions meant to facilitate discourse need a tighter framing to accomplish the survey’s goals. Simultaneously navigating CUNY’s Human Subjects while finalizing the project’s design makes me feel like I’m in a constant state of frustrated revisions, which feels a little ironic considering I submitted my final a week ago. I am thankful my collaborators and I designed this project to have a pilot phase that focuses more on our learning from the project’s design before taking the survey and digital platform to scale.
While I am anxious, frustrated, and a little scared, I also realize I feel this way because I’m genuinely excited and passionate about this project. And part of my hesitancy comes from the ways this class consistently centered digital humanities’ commitment to social justice praxis; critical race theory, intersectionality, and political strategies were treated as central, rather than niche areas of DH, and I feel incredibly lucky that this is my introduction and foundation. The skills I acquired over this semester have enhanced my approach as an activist-scholar, a public sociologist, and an accidental humanist.
And just like that my very first semester in the DH program is done. While this year of learning was unlike any other, I’m so impressed with how smooth it went and how easy it was to transition to remote learning. I’m thankful we have access to technology that lets us learn and continue with our grad careers. I’m also incredibly thankful to have had such wonderful classmates! Everyone is so intelligent, kind, and thoughtful, and I’m looking forward to working with you next semester!
With this final project I did feel a little overwhelmed when thinking how to piece it all together, but I also felt confident in my abilities to fill in the gaps that I didn’t already know. Because this was my first semester (and it’s been 5 years since I left undergrad) I was feeling a little apprehensive about writing a paper again. However, the final project guidelines that Matt provided were a great roadmap, and I felt better knowing that I had something to follow when getting my thoughts out. As I discovered throughout the whole fall, it was also a challenge balancing full-time work and life responsibilities with classwork. In this area, I’m actually thankful to have saved time commuting and running around the city since there’s not a whole lot we can do these days. But it’s worth acknowledging the emotional and mental stress we’ve all been put through this year, and I’m proud of us for showing up each week to share thoughts and learn while working towards these final projects. Again, I’m inspired of all of you and in awe at the project proposals you came up with. Brianna mentioned this in our last class and I’m reiterating here, I want to work on all of these projects!
For my proposal of a tool to help farmers and community orgs have better access to the food supply chain, I was definitely ambitious. But I thought… hey, why not? I think the majority of the impact here is revealing the gaping issues that exist and prevent farmers from staying in business and struggling families surviving. So even if the problems here are just too large for any single tool to solve, let alone a proposal from only a graduate course and not some major government program, I think it’s worth doing the research to shed some light on the ways these groups are struggling. I learned so much about the complex and byzantine food supply system that currently runs things, and got insight into heartbreaking figures that reflect how many families are struggling to put food on the table. All this to say, it helps to break things into pieces rather than try to bite off everything all at once. Thanks to Matt’s notes when I initially submitted my proposal last month, I broke up the whole project into phases that could be used as stepping stones that would make up one powerful, multi operation tool, or used individually depending on the needs of the user. I think we all stumbled across this over the semester but again, scope creep is real.
Many of us also shared worries about not knowing the full tech requirements and roles to build our projects. And I think that’s OK! I know I only scratched the surface of this area while doing research for this project, and I’m excited to meet new experts and learn more about these roles in future DH classes. It can be frustrating to not know everything or be an immediate expert, but I know the learning is in the journey and we’ve only just begun. Similarly, I’m taking these DH courses only part-time and will slowly work towards the finish line. I’m jealous when I hear about the other classes many of you are taking at the same time. They all sound so interesting! I get antsy and want to bite off more than I could handle with everything else I’m juggling. But then I shift my focus and get excited about the amazing classes coming up. I hope you all feel the same way because this DH program is fascinating.
Thanks again for a great semester! Have a wonderful break and see you in the new year. Feel free to find me on LinkedIn, social media, etc. to connect!
Thoughts on Class- When I first started looking into possible majors to start my graduate work I decided I wanted to take a risk. Sure I could of continued on my path of English Lit and Journalism but a part of me (very strong part of me) was not satisfied with what I was doing in regards to both of these subject areas. I wanted to explore a new territory, one that was completely foreign to me. One that I know would help me develop new skills but also challenge me along the way. Somewhere along my research trying to find a subject that would do that for me I stumbled upon Digital Humanities. Truth be told I had to google the definition of this field cause I had never heard of it before. The search results that came up both confused and intrigued me. I didn’t know what this subject entailed but from what I could see it included a little bit of everything. From there I took a gamble and decided to apply for the Masters DH program at the Graduate Center. When I first learned of my acceptance I was elated but soon a feeling of panic also set in. I was coming into this with no prior experience, although experience wasn’t needed the egoist in me didn’t want to come off like I didn’t know what I was doing. But I didn’t know what I was doing . Every week in class I listened to my peers wise words and insight and I sat there not knowing what to say. I felt intimidated but also so amazed by the thoughts you guys came up with. This class was mentally stimulating in so many ways. Professor Gold did a great job in allowing us students have an open space to discuss and converse. I soon realized that I wanted to navigate this class the best way I felt I could. I wanted to listen, learn and absorb. If I didn’t have the right words to try to convey what I wanted to I gladly listened to my peers do it. Maybe in the end I do have some regrets about not participating that much but I’m happy with how this semester went. Thank you to all of you guys for being such a great class.
Final Project- As the semester was nearing its end I knew it was time for me to start thinking of a topic for a final project. As I racked my brain for ideas on what I wanted to do my project on I unfortunately kept hitting dead ends. I initially wanted to do something based off of social media and how I can somehow come up with a way to create filters on platforms to help separate factual information from posts that are put up to spread lies. I know some sites already do this but I wanted to create an upgraded version. However this idea didn’t end up going anywhere as I quickly overwhelmed myself with the prospects of what I needed to do to complete this project. I had no idea where to start or how I would expand on it. So in a last minute decision I decided to start fresh and look at the prompt to get a new idea. Although this project would of been great practice I figured I wasn’t ready to dive into grant work just yet. I’m keeping the social media project in the back of my head for the future but for my first semester I wanted to go with the seminar paper option instead. Labeled under pedagogy the seminar paper I chose to go with involves creating a syllabus for a hypothetical DH class. I immediately gravitated towards this as I knew it would allow me to be creative. As a first year DH student it may come off bold and pompous to feel as though I have authority over what should be taught in a DH class but in my opinion I just saw this as an opportunity to add to the conversation that is already being had in DH. What can be done to improve this field? What should be allowed in DH? How far should it expand? I wanted to showcase what I thought was most pertinent in this field and how I feel a class of this subject area should function. In my paper I label my class as a quasi workshop setting. Most of class time will be spent doing hands on projects such as text mining movie scripts and books and using Google Earth to track the location of their parents’ hometown like Mayukh Sen did in “”Dividing Lines. Mapping platforms like Google Earth have the legacies of colonialism programmed into them“. These are just some examples but students will use what they know from readings and class discussions and apply it to physical work. Some of my projects are directly inspired by ones we had to create for this class, though I did make a few minor tweaks. Along with projects I also added a blog post element. Over the course of this class I thoroughly enjoyed both writing and reading everyone’s posts on Cuny Commons. I felt that they were a great way to express ourselves in a class setting without having to be too formal. Blogs for my hypothetical class were created for students to communicate their thoughts along the semester. As an instructor I want to know what’s going on in my students minds, I want to know if they’re engaged with the material. The blog posts and the projects will make up for most of their grade and participation counts for 10%. I would ideally want student to participate in class but I know from my own personal experience that doing so is not always easy. The discussions we have in class will revolve around reading material I have provided. Some texts were taken from Prof. Gold’s syllabus as I felt they worked well with certain subjects I wanted to teach. Others were taken from other DH syllabi I found on the web. I looked into each one and decided which worked the best. Additionally I also added a few articles I had found on my own that I felt added extra food for thought. Based off of the readings and projects I crafted the two final project options. One will be a 10 page paper based on a specific term or debate that came up in the readings or a creative project that features students utilizing a computerized DH tool to expand upon a in class project. This will also include a 5 page paper explaining their process and any problems they encountered. In all I wanted my syllabus to mix in traditional elements of a DH class with an updated twist. When researching DH syllabi I’ve noticed many are densely populated with reading material, most of which I felt could be done without. Maybe I feel this way because I geared my syllabus towards a undergraduate/elective level but I personally believe students will be more captivated by this field if they were given more opportunity in class to perform rather than read. I think this intro course gave us a pretty good balance of assignments and readings. For my own class I simply wish to expand on it.
First and foremost, I want to reiterate what others have said – this class has been so enlightening and interesting. Honestly, I didn’t know what to expect from DH and I’m so glad I decided to join this program. Thank you all (and Prof. Gold) for your ideas and openness!
I’ve been procrastinating writing this final blog post but it’s been the case all semester that after reading what my fellow classmates have to say, I’m inspired to contribute. Perhaps, it’s good that I took some time to reflect on the final proposal process. I’ve just re-read my proposal and am reminded of some of the issues I experienced when writing it. Echoing others’ comments, I had a difficult time navigating between writing a paper and a grant proposal. How much research should I be doing? – I could easily have added more pages and sources just to explain the rebus and its history. Is my writing persuasive enough that someone could theoretically want to give me money to do this project? – my proposal sounds somewhat repetitive because I was probably thinking about this too much. Are the projects mentioned in my environmental scan appropriate and relevant? – remains to be seen. In hindsight, I wish I had started this process much sooner so that I would have time to consult with others like Micki Kaufman, the other fellows or the library (great job Elena and Bri)! But, I’m grateful to have had the opportunity to write this proposal as a sort of practice for the future.
Anyway, here is part of my abstract to refresh your memory: Reading the Rebus is an online, visual archive of 19th century British and American rebus ephemera. The project aims to make a select group of historical rebus ephemera accessible in an engaging, collaborative and interactive format to scholars in diverse fields such as linguistics, history, education, communications, design studies, and visual arts, as well as members of the general public – opening up new possibilities for discovering how we see and interpret visual information. Each rebus puzzle will be treated as an interface of inquiry to conduct close reading experimentations, translations and interpretations by audience participants. Reading the Rebus challenges the notion of traditional texts by using humanistic qualitative analysis, while also contributing to the history of language and visual communication from cuneiform and hieroglyphs to contemporary, digital emojis.
And so in the spirit of the rebus, I leave you with Xmas holiday greeting!
In summarizing my experience morphing together a grant proposal and a final class paper for our course, I would say that the process presented an interesting ambiguity perhaps best framed by the following question: In terms of the readership of this kind of hybrid paper, how different is an interlocutor represented by seminar participants from the judges of grant competitions in grant making organizations? I would have to admit that, while it might depend on particular grant making personnel, writing with either a generic foundation or the federal government in mind shifted my sense of critical analysis and academic freedom. With a seminar paper written largely in conversation with course readings, instruction, and class discourse, there seems to be plenty of space for imaginative and perhaps even heterodox inquiry. Grant seeking proposals arguably require conformance with the norms, models, and ideologies of the administration of the grant making organization. Does autonomy of academic work matter and if so how much autonomy can be sacrificed without undermining principles?
Certainly academic research in such areas as nuclear and military projects poses stark ethical dilemmas. To what extent are ethical questions relating to funding relevant for DH? This line of thinking quickly leads to difficult yet emancipatory critiques of the university and higher education, problems of neoliberalism, and the stunting realities of austerity politics. Yet the imaginary endures of the possibility of fully funded academic programs (instead of depending so much on the NEH) that are autonomous from government institutions and private philanthropies. If the critique of the neoliberal university is valid, is it not incumbent upon members of the university community to consider the extent to which projects challenge either directly or indirectly the hegemony of the neoliberal agenda? Perhaps in the end this line of thinking points to the personal evaluation of doing the right thing, at the right time, by the right people (and the sobering doubt that my efforts might ultimately be helping to guide change in the direction of the slow motion train wreck).
Given this ambiguity I was wondering what a paper would look like that combined critical analysis with a proposal for funding. As it turned out, it was yet another generative and curious experiment to mixin and mashup some of the language of critical analysis with the language of grant seeking. Perhaps therein lies the art and craft of interfacing with the larger funding enterprises. Looking back, though, I wonder how much of the language of critical studies is palatable to larger grant making institutions. While there are arguably a handful of small foundations comfortable with heterodox projects that question dominant ideologies, projects that might resemble such efforts as Torn Apart/Separadoes or wikileaks would seem to be out of scope for many if not most grant making organizations. Or perhaps this is the line that separates responsible academic work from investigative journalism.
In reflecting on the idea of a Zoom App Integration, it’s not entirely clear the extent to which such an app integration might unequivocally contribute to challenging the neoliberal agenda. Perhaps one possibility lies in the potential for creating a context for learning that in some way maintains affordances for speaking truth to power, questioning all assumptions, and insisting on the fundamental dignity of every human being and the biosphere. In the spirit of experiment and open ended inquiry (and other qualities embodied in our class), I am left with a sense of work to be done and how to do justice to the transformative dialog, readings, and instruction I am grateful to have experienced in this class and community.
For my final project, I proposed an extension for the text analysis tool suite, Voyant. During my first experience with this tool, I came across the need for a mixed text analyzer. Since I couldn’t find one, or at least one that was open source, I decided to contact Voyant and see if they would be interested in improving their already great device.
After speaking with Geoffrey Rockwell, one of the creators, I became intimated by the thought of the amount of work the would go behind making such an extension. I was convinced that it would be a simple tweak to their tokenizer, but the extension would ultimately need an experienced Javascript programmer and possibly a linguistic scholar. Rockwell pointed out that the way around analyzing mixed text is to first separate the corpus into two (or more depending on how many languages present in the corpus) and then import the texts individually to Voyant. I was not too thrilled with that idea. He told me aboutVoyant‘s Spyral which was design with digital humanist in mind. After receiving various suggestions on different extensions, the team at Voyant decided to construct a tool that would tailor the explorer’s newfound data based on Javascript coding. By importing both text and code, a user can essentially make the different extensions work to accommodate the user’s needs. Therefore, he suggested I could either learn Javascript or ask for help from a programmer to tweak the tokenizer myself and ask it to recognize and categorize the mixed text. I didn’t want to do that either.
I proposed having an extension that would work alongside the other tools like Mandala, and Termberry to identify and classify the languages, determine the relationships between each other, and to compute how much of each language was used in the entire document. I sent over a sketch as well as a list of a few of the Voyant tools that could be modified to fit this extension.
What I didn’t realize is that even though I write bilingually most of the time (not just informally through mobile text messages and social media posts, but also when writing scripted television and other forms of storytelling), the style of writing is not widely accepted as formal or as style scholars are interested in analyzing. After researching, I found not digital humanists, but prominently analysis in customer service and marketing would be interested in this tool. This is because the writings they investigate are informal, digital consumer reviews, and social posts which tend to be bilingual.
I argued for the benefits in the humanities including literary scholars analyzing bilingual and multilingual poems, to more social linguists that would like to investigate the cultural influence behind these pieces as well the usage of syntax in such texts. However, after finding an experiment on such a tool done back in 2015, I understood that a more practical use for this tool might be in the pedagogical sector. Professor Siu Cheung Kong along with his colleges in Hong Kong, China created a plug-in on Moodle, an e-learning course builder for educators. The plug-in would allow educators to analyze the works of ESL and TSEOL students.
After the research I had a difficult time completing the last two section of this paper: work plan and dissamination. Other than an HTML and C++ lesson in high school, I never had any training in building any digital tool. I knew I needed help but I didn’t know where to start. I was sure of what I wanted the tool to do and how it must work seamlessly with Voyant, but other than needing Javascript, I was lost. I didn’t know the timeframe nor the work behind creating something like this.
Needless to say, I wanted to challenge myself and I did. I could have asked for more guidance in both the construction of this tool and the writing of this final paper. I needlessly struggled alone even after learning how much time and human power it takes to construct any digital humanities project, especially when the “digital” part is not your strong suit!
I really didn’t know what to expect when I joined our first Zoom class in August—a mere 4 months ago in calendar time and closer to 40 years ago in experienced time. How would I adjust to being in school after being so long away from it; how would grad school be different from college; how would remote learning even work? I was stumbling every time I even tried to describe what Digital Humanities (DH) was when people asked me what I was studying. “You know, like humanities, but digital.” Little did I know…
The vast scope of our readings, our care-full and engaging conversations, the most amazing and thoughtful and socially justice–minded project presentations everyone gave—I’m in awe of all of us and what we accomplished together. Thank you doesn’t fully cover it, but THANK YOU so much for everything. I can’t imagine a better introduction to the program, and I am beyond excited to start building our projects together next semester.
As others have mentioned, this final project felt very daunting. What do I know? I’m a little into the macabre, and I just wanted to map a few cemeteries, and I don’t even know that much about mapping. Am I really adding to the field at large? So I admit I called on my old friend procrastination, and I procrastinated. And then procrastinated a little more, for good measure. But even as I was putting off actually writing, ideas were stewing in my head.
And I’m so grateful to Prof. Gold for introducing me to a student further along in the program who is also interested in cemetery studies. She was so supportive and encouraging in our conversation, and she helped me realize there is indeed a place for my mapping idea in DH. And she led me to a recent anthropology dissertation from a Graduate Center alum about the historical deathscape of New York City from the colonial period onward. And that got me thinking, maybe it’s not too late, there really are a wealth of resources available within the GC. The mapping part of my mapping project was throwing me for a loop, and I remembered that Olivia Ildefonso led an intro to ArcGIS workshop, and as a digital fellow she offers consultations. And I’m so grateful to her for fitting me in last-minute at the end of the semester. She really helped me think about what my data set could look like and helped me reign in my scope creep. (At least I think she did; Matt, if scope creep is still an issue in my final proposal, just know that it was WAY worse in earlier drafts.)
So my final proposal is about creating an ArcGIS StoryMap of the cemeteries in Manhattan in 1820 compared with 2020. I’m most interested in capturing the obliterated cemeteries—which are in all five boroughs, but the most documented ones are in Manhattan—as I find it very exciting to be mapping things that don’t quite exist anymore. In addition to providing great numerical symmetry, I think these years are also significant within the scope of my project. New York City was the largest city in the country by 1800 (then just Manhattan), and the population more than doubled between the 1800 and 1820 Census. And the most significant legislature on burial bans in Manhattan wasn’t passed until 1823 and after, so I think 1820 captures a time of great growth (and death), and it predates laws that greatly altered the deathscape. Many of these laws were passed in direct response to outbreaks (namely of cholera and yellow fever), and I think it will be very interesting to visualize how they affected the landscape of the city at a time when we’re still understanding how the COVID-19 pandemic is affecting us in the present (or very recent past, as the case will be next semester).
As I was working, I was so entrenched in reading about cemeteries and finding out how my project would relate to/expand on other work in this area that I almost completely forgot about our course readings. Matt’s sage advice on rereading the proposal prompt saved the day, and I had a mini breakthrough once I started thinking about the landscape of New York in relation to our readings on infrastructure. I knew that it bothered me that there has been so much cemetery obliteration—even as part of my brain thinks that it’s not an environmentally sustainable practice and I have many complicated and contradictory questions about it being the “best” use of space—and I knew that at least some of the obliteration was purposeful, and not just because of financial interests. There are power structures that made these choices, who have built up and altered the way we live in and experience this city. And this infrastructure necessarily limits those experiences as much as it may enable them. So in mapping what has been removed, I dare to hope that my project is both an act of care and of disobedience.
Again, thank you all. It has been an utmost privilege to be in this class with you and share this experience. See you next semester!
This semester has been a series of “firsts” for me. I’ve had my first experiences with remote classes, digital text analysis, and voice acting; it’s my first semester in a graduate program and my first semester at CUNY, and of course, this semester has included my first attempt at writing a grant request.
First and foremost, this class’ final project forced me out of my comfort zone; very far out of my comfort zone, in fact. I don’t know how many were in a similar situation to me when the project was assigned, but going into the project, I had for most intents and purposes, no experience in the realm of grants. In all honesty, the closest I’d come to reading or writing grants was reading a collection of science fiction stories written in the format of grant requests for developing large-scale tech projects entirely infeasible in reality.
When I first came up with the idea for my grant, I was desperately grasping for concepts from this semester and my background that I was familiar with. In the case of the former, I selected text corpuses, in part due to how much I enjoyed working with Voyant and Google NGram earlier this semester, and because I’ve familiarized myself with corpuses moderately more as a result of doing a final project in another class relating to them (I produced a syllabus for an undergraduate class that focuses on text corpus creation). In the case of the latter, I chose rhizomatics, as Delezue and Guattari were major inspirations during my undergraduate career, and I felt comfortable thinking about and using their work.
After receiving feedback, I was a little worried about my ability to successful produce a grant request. However, I decided that I’d already gone this far, and chose to stick with my idea of a collaborative corpus creation website influenced and inspired by Deleuzian philosophy. Admittedly, now that I’m done with my final project, I’m not sure how I feel about my product. On one hand, even though this is a first attempt, I fear that it wasn’t up to par. On the other hand, I’m incredibly proud of myself for even writing and completing my first grant request, and if nothing else, if it wasn’t for this project and Professor Gold, I would have never come across Stephen Ramsay’s work (as soon as I’m done with the rest of my finals, I need to give the ‘Patacomputing section of Reading Machines another read. I’m so happy I got to meaningfully interact with work that references Alfred Jarry, even if briefly).
This semester was more or less objectively a significant outlier in my educational career. I think that’s the case for the vast majority of people in the world, but at least I got to spend it taking a course as stimulating and thought-provoking as this one. I’m very thankful to have had an opportunity to learn from Professor Gold, and to have had all of you as classmates. Happy holidays, and I hope someday, we all can meet in person.
Need help with the Commons?
Email us at [email protected] so we can respond to your questions and requests. Please email from your CUNY email address if possible. Or visit our help site for more information: