This semester has been a series of “firsts” for me. I’ve had my first experiences with remote classes, digital text analysis, and voice acting; it’s my first semester in a graduate program and my first semester at CUNY, and of course, this semester has included my first attempt at writing a grant request.
First and foremost, this class’ final project forced me out of my comfort zone; very far out of my comfort zone, in fact. I don’t know how many were in a similar situation to me when the project was assigned, but going into the project, I had for most intents and purposes, no experience in the realm of grants. In all honesty, the closest I’d come to reading or writing grants was reading a collection of science fiction stories written in the format of grant requests for developing large-scale tech projects entirely infeasible in reality.
When I first came up with the idea for my grant, I was desperately grasping for concepts from this semester and my background that I was familiar with. In the case of the former, I selected text corpuses, in part due to how much I enjoyed working with Voyant and Google NGram earlier this semester, and because I’ve familiarized myself with corpuses moderately more as a result of doing a final project in another class relating to them (I produced a syllabus for an undergraduate class that focuses on text corpus creation). In the case of the latter, I chose rhizomatics, as Delezue and Guattari were major inspirations during my undergraduate career, and I felt comfortable thinking about and using their work.
After receiving feedback, I was a little worried about my ability to successful produce a grant request. However, I decided that I’d already gone this far, and chose to stick with my idea of a collaborative corpus creation website influenced and inspired by Deleuzian philosophy. Admittedly, now that I’m done with my final project, I’m not sure how I feel about my product. On one hand, even though this is a first attempt, I fear that it wasn’t up to par. On the other hand, I’m incredibly proud of myself for even writing and completing my first grant request, and if nothing else, if it wasn’t for this project and Professor Gold, I would have never come across Stephen Ramsay’s work (as soon as I’m done with the rest of my finals, I need to give the ‘Patacomputing section of Reading Machines another read. I’m so happy I got to meaningfully interact with work that references Alfred Jarry, even if briefly).
This semester was more or less objectively a significant outlier in my educational career. I think that’s the case for the vast majority of people in the world, but at least I got to spend it taking a course as stimulating and thought-provoking as this one. I’m very thankful to have had an opportunity to learn from Professor Gold, and to have had all of you as classmates. Happy holidays, and I hope someday, we all can meet in person.
(Disclaimer: I was looking back through my posts for this semester to make sure I had posted everything required, and I noticed that I never posted this. Thankfully, I still have the document saved to my computer, so I’m posting it here now. Utmost apologies.)
Ryan Cordell’s How Not to Teach the Digital Humanities was one that caught my eye as soon as I saw the title. Upon actually reading it, I was pleased with its contemplative and analytical tone, but surprised at the sorts of criticism it contained, specifically regarding Cordell’s idea that pieces grappling with the question of “What is DH?” were commonplace enough to arguably form their own genre. This definitely got me thinking about my own personal application of the digital humanities: do I spend, or have I spent too much time questioning what it is? Should I be focusing less on defining or considering what the digital humanities is, and more on working within it?
In reference to his teaching experiences in the digital humanities Cordell notes that he “[has] found ‘Texts, Maps, Networks: Digital Literary Studies’ a more productive and stimulating class than its immediate predecessor, ‘Doing Digital Humanities.’” At first, I took this to mean that he finds digital humanities courses with more specific focuses to be preferable to ones that have a more general, less defined theme. However, after reading through the article a second time, I took notice of Cordell’s discussion of interdisciplinarity.
At a glance, the title “‘Texts, Maps, Networks: Digital Literary Studies’” suggests interdisciplinarity. The first half of the title defines three semi-related topics, and the second half serves to contextualize those topics within a potentially-separate topic. Cordell writes that “that interdisciplinarity is grounded in [his] training in textual studies, the history of the book, and critical editing.” As I continued further into the article during my second reading, I also realized that his points in the “But Don’t Panic” section of the article each lend themselves subtly to interdisciplinarity. At first, I thought this slightly contradicted his claims about the digital humanities “only [being] a revolutionary interdisciplinary movement if its various practitioners bring to it the methods of distinct disciplines and take insights from it back to those disciplines.” However, perhaps it’s meant to demonstrate that because the digital humanities lend themselves to interdisciplinarity in the first place to a degree, it’s not necessary and in fact maybe even excessive to actively pile more interdisciplinarity into it.
Something that absolutely stuck with me from the piece is his mention of a student using Tumblr as a platform to analyze fandoms. Especially recently, Twitter seems to be dominating the web as the go-to social media site for scholarly projects. While Twitter absolutely has value for such projects, constraining oneself to a single social media platform is almost certainly limiting. While this is a relatively minor part of the piece, it was extremely refreshing – maybe this was only the case for me, though.
I bring this up because it led me to explore the keyword “blogging” on Digital Pedagogy in the Humanities. I’ve explored a collection of words on the site for my other classes, but blogging never struck me as one that I’d want to examine. Out of the artifacts there, I was most drawn to Karen Cooper’s graduate-level class syllabus, “Social Media and Digital Collaborative Applications: Microblogging.”
Upon closer examination, the syllabus was significantly removed from most syllabi I’ve looked at critically, although this is in part due to me having few opportunities to look at graduate-level syllabi. That aside though, Cooper’s choice to make “weekly microblogging, analysis, and implications” worth a very significant part of the grade was a very interesting one, at least to me, although it made sense considering the course at large. The fact that the course also “has no required [textbooks]” caught me off guard as well, but again, it’s not the most uncommon choice, especially since the syllabus implies online readings. The syllabus depicts the course as strongly distinct and incredibly focused. While my own distaste for platforms such as Snapchat would steer me away from running a course just like this one, I can’t help but want to try setting a syllabus for a course in the same vein as this one – focusing on the usage of one-to-three platforms and building curriculum and assignments around them.
Earlier this semester, just after we finished our mapping projects, I attended a workshop on QGIS run by Professor Olivia Ildefonso. Before the workshop, I was in the mindset of having just used QGIS to complete my first project. While it was a small project and perhaps rather “selfish” compared to some of the other mapping projects I took a look at for inspiration, I was very proud of myself, and looking forward to learning to do more with QGIS.
I came equipped with a collection of questions about the aspects of QGIS I found difficult to deal with while working on my projects, specifically dealing with adding types of layers and keeping layers organized within the program. Ildefonso not only answered my questions and cleared up confusion I had about how vector layers functioned, but also informed us about two very key aspects of the program that I had no idea about – the robustness of layer attributes (that is, what one can do with a layer by adjusting its attributes) and using QGIS to isolate specific regions in map data. If I had known about the latter, I would have had significantly less trouble during the project. I also learned that when trying to make a legend, QGIS takes variables and variable names directly from the map exactly as they’re recorded, meaning that to change variable names, one has to change them on the actual map. This answered my dilemma about designing legends with the software.
Perhaps the most interesting piece of information I learned during the workshop was that projects of non-Earth planets exist and are apparently available. I haven’t gotten around to experimenting with them yet, but at some point after the workshop I came across a map projection for the surface of the planet Mars. To be sure, I have something of a pipe dream about someday reaching a point where I’m proficient with QGIS or similar software to the degree that I can create the map of a fictional world and then plot data on it. I know how silly this may seem, but in all seriousness, mapping data on a fantasy map could be an interesting creative exercise, and it could also be good for creating visual aids.
I asked Ildefonso about her stance on combining software while working with data mapping, and she gave an answer I didn’t entirely expect. She asserted that combining software, if doable, is entirely reasonable: however, one of her professors colloquially described using image editing software to touch up or create graphics a product made with data software as a form of “cheating.” In the end though, she argued that “whatever gets the job done is what [one] should do.”
Towards the end of the discussion, Ildefonso discussed plugins she recommended. She praised Michael Minn’s MMQGIS collection of Python plugins for the amount of valuable content and versatility it adds to QGIS. MMQGIS allows for much more intricate manipulation of vector map layers. I tested it for a little for myself and I have to say I’m impressed with its capabilities. If I ever do another project with QGIS, I’ll probably make use of the collection.
As the semester’s progressed and I learned more and more about the conclusion of this class, I’ve grown progressively more and more intrigued, yet also more and more intimidated by the prospect of writing grants. This is in part due to people in my life telling me that I should at least giving going into grant writing a chance. In part because I’ve been recommended grant-writing as a career choice, it’s furthered both my curiosity and anxiety: on one hand, this final project could be a means to significantly further one’s career, but it’s also all the more daunting in all its formalism. I think I’m not alone when I say that this is my first time consciously doing anything even related to grant writing, outside of, for instance, more general, casual project proposals.
Tips on Applying for a Preservation & Access Award on by the Division of Preservation and Access Staff on National Endowment for the Humanities website was both informative and soothing. Its “Get a Little Help From Your Friends” section really emphasizes the fact that even if one seeks funding for a solo project, one should not be afraid to reach out and work with the connections one has. Additionally, as I’ve begun to set up my own final project, the article as a whole has served as a quick and easy general reference. That is, the article succinctly lays out key information in a way that lets it be used as a sort of a (rather general) checklist for what one should aim to include in one’s grant, as well as a guideline for making sure one is generally on track.
While Tips on Applying for a Preservation & Access Award, at least for me, functions best when I have it in a browser window in the background while I work on my proposal, Sheila Brennan’s Planning Your Next DHAG series is much more heavy-duty because of its multi-part nature, but in turn, it’s much more detailed and informative. I have to admit that I’ve read through the whole of it a few times out of anxious compulsion. I like to believe this has helped me in some manner.
The part of Brennan’s article I keep open in the tab next to the one I have Tips on Applying for a Preservation & Access Award in is her list of “six evaluation criteria,” found in Idea, Audience, Innovation, Context. When I’m reading back through what I already have written, I’ve found it very helpful to try to connect each paragraph I’ve written back to one of Brennan’s criteria. When I find a paragraph that I can’t connect back, I generally attempt to figure out if that’s for a reason or not, and whether the paragraph can stand on its own, or if it’s poorly-conceived, too filler-ridden or off-topic.
Earlier this week, I found myself thinking about pre-digital text mining a lot. Of course, the sorts of analysis we use tools like Google Ngram Book Viewer, Voyant, and JSTOR Labs Text Analyzer for have been in existence for far longer than the Internet, albeit in a different forms. Indeed, in my past, I’ve used much less advanced means to “mine” texts: during my junior and senior years of college, I spent quite a bit of time doing just that with Dante’s Divine Comedy, comparing different sections of it to one another, as well as to other texts. I’ve been told about and recommended Ngram and Voyant on many, many occasions in the past, but I’ve never had an excuse to explore them deeper. This project gave me the chance to explore not only those two, but also JSTOR Labs Text Analyzer.
I decided to perform a different experiment with each tool. While Voyant was described as the “easiest” of the tools, at first glance, Ngram drew my attention most due to the fact that it works of a predetermined corpus. This made me think about how reliable it could really be. At best, if one views this corpus as a “standard” of sorts, it could be used to compare multiple studies that used Ngram. However, I find myself wondering if information gained through Ngram could be potentially biased or skewed compared to information gained through other text mining tools that let you establish your own corpus.
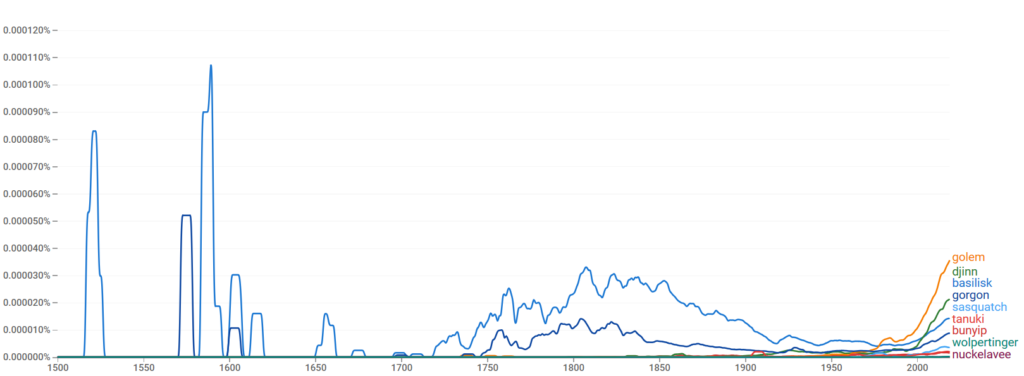
In any case my first experiment wasn’t entirely in line with the project prompt, but I was curious, and I wanted to start somewhere. After reviewing Ngram’s info page, I decided to enter the names of a collection of 9 beings from different folklores and use the longest possible time range available to me (1500-2019). I made sure not to pick anything like “giant” due to the fact that “giant” is a word we use regularly with no attention paid to the associated creature. For consistency’s sake, I also didn’t pick any beings that are explicitly unique, such as gods.
It gets a bit cluttered at points, but I think it presents some interesting results, especially about Ngram’s corpus. It’s immediately clear that the basilisk has the highest peak and overall mentions of any being in this experiment, and even in our time, is only surpassed by two other beings. We also have a pretty clear second place, with the gorgon, who is just below the basilisk, even today. With regards to today though, the golem and djinn went from being fairly obscure to being most and second most popular.
With regards to the former two, the basilisk and gorgon this may indicate a very strong bias in Ngram’s corpus in favor of Cantabrian-Roman (basilisk) and Greek (gorgon) – that is, Western – pre-20th-century mythological texts. Alternatively, it may indicate that writers during those times were using those words more often in figurative language and metaphor (this may be completely arbitrary), or that more editions of myths regarding those creatures came out during those times. With regards to with the latter two, the golem and djinn, respectively from Hebrew and Arabic folklore, have received much more media attention as time’s gone on due to the growth and popularity of the fantasy genre.
The other 5 beings, from most to least frequent in mentions, are respectively from North American, Japanese, Oceanic, Germanic, and Orcadian folklore. The Tanuki has its first uptick in popularity around 1900, or just before the death of Lafcadio Hearn, responsible for some of the first texts on Japanese culture available to a mainstream English-speaking audience. Additionally, while the wolpertinger (Germanic) and nuckelavee (Orcadian) are Western myths, they’re the two least popular, which doesn’t coincide with the apparent bias toward Western mythology. Perhaps it’s specifically a Greco-Roman bias? I would probably have to conduct a more in-depth study.
Moving on, I tried Voyant next. I was excited to upload documents and even experiment with my own writing, but I was surprised to see that I could upload images and even audio files. The first trial I gave it was trying to get it to upload the graph I posted a bit ago, and then a MIDI and an .m4a file I found in my downloads folder. I was saddened to see this:
But I pushed onward and found that Voyant certainly tried to mine the audio file I fed it. Of course, it spat it out as a bunch of garbled text, but I might make a foray into the realm of trying to get practical use out of getting a text miner to mine images and audio in the future. For the time being though, I decided to stick with something more conventional. I tossed it a .txt file with a single haiku on it that I had lying around for a proper test run, and then got to my real experiment. I uploaded a folder of between 40 and 60 Word documents containing poems (certain files contained more than one poem) I wrote since 2013 just to see what would happen, and I got the following lovely word map:
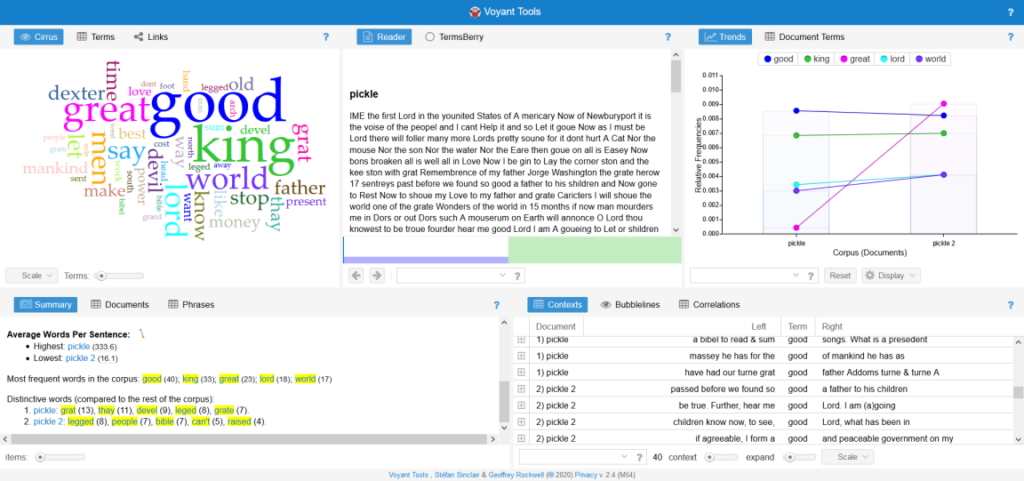
After doing so, I realized there wasn’t a lot of data to glean from this that wasn’t self-indulgent, and at points, personal. Apparently though, I really liked the word “dead” (note: there WAS a poem in there about wordplay regarding the word “dead.” it’s a lot more lighthearted than you’d think). My next, and for the time, final usage of Voyant involved A Pickle for the Knowing Ones by Timothy Dexter: using the “Split Pickle” view of the piece offered by this site, I compared the original text of the piece’s first folio to the site’s “translated” version. For those unaware, Dexter dropped out of school at a young age and was largely illiterate.
Note: “pickle” refers to the original text, whereas “pickle 2” refers to the “translated” version.
Of note, in the untranslated version, the average sentence length is 333.6 words. With this corpus, something of note is that all of the “distinctive words” in the original text are… not really words. The fact that the original has 8 instances of “leged” while the translated version has 8 instances of “legged” is a testament to this.
Finally, I experimented with JSTOR Labs Text Analyzer. Here, I decided to go with an essay I wrote on the overlap between architecture and the philosophy of architecture, traditional narrative, and video game narrative during my senior year of college, and I was pleasantly surprised to the point of being slightly unnerved with the result due to its accuracy.
“Mathematical objects” absolutely includes architecture in the context of the essay.
There was a little less to experiment with on JSTOR, so I mostly left it at that. The number of related texts I was offered was certainly appealing though, and out of the three tools I experimented with, I think this text analyzer would be the one I would use for research, at the very least.
For my mapping assignment, I went somewhat off the rails, both in terms of subject matter, and in the sense that I integrated an element of comparing data on my map. My map, created with QGIS, displays 25 relatively-eastern US states, shows which of them I’ve dreamt about, and how many of my digitally-written pieces mention them.
The completed map. Important note: for Illinois, I actually found 0 instances of it in my writing – the number I recorded is the number of instances of “Chicago.”
Why Did I Do This? I know this idea sounds at the very least unusual, if not entirely unfounded, or even unreasonably arbitrary. However, I find myself thinking a lot about two topics more as of late: the content of my dreams, and my old writing. I think the cause of this is almost certainly related to the fact that the COVID-19 pandemic restricts my ability to interact with others, and so I often find myself thinking about more self-centered matters like these. I took inspiration of the project’s offered second and fourth prompts for this map: dreams, at least in most mainstream schools of thought, are not traditionally able to be mapped, and while even I doubt it sometimes, I can’t deny that I am, at least to some degree, an author, and I have works to my name.
I chose these 25 mostly-eastern states for two reasons: first, sadly, due to the constraints of QGIS, and I know this goes against the project’s first offered prompt. I had some difficulties getting the entirety of the US to render well when I set up a print layout. Second, due to constraints I wanted to set myself. 25 is half the states in the US, and the eastern side covers my home, and most of the places in the country I’ve traveled to physically.
Something that surprises me, looking back, is that this was my initial idea for the project, once I had determined what tool I’d use. I had a feeling that I’d come up with something more substantial or more pertinent to current events, but I suppose this must have spoken to me on some level. Maybe I was partially inspired by some of the work I’ve done in another course, Methods of Text Analysis, where I’ve been using Python to examine aspects of texts such as the number of times words appear in or across them, or the context of those words being used.
The Method
This was my first time working with QGIS, but not my first time mapping something. To be sure, in my line of work, making maps of places that don’t exist is something I have to do very often, and when I first started thinking about this project at all, I thought about doing something along those lines – maybe using one of the mapping tools to create a map of a fictional nation. I quickly realized that this was rather outside my abilities, and I started thinking smaller.
When I first started with QGIS, I mostly experimented with what sorts of files it could take – I thought perhaps I’d have a file lying around my computer somewhere that it could read by chance. After realizing this wasn’t the case, I looked up some tutorials, and went from there, deciding to focus on using a print layout at first. The first challenge I ran into was cutting down on the number of titles, subtitles, markers, errant lines, and names of places from world map I was using. Eventually though, with trial, error, and some guidance from the tutorial, I eventually managed to be successful in this regard.
To gather data, I looked back through personal notes and my own memory to find places I’d dreamt about. Then, I checked through each of the pieces in my collection for mentions of the states I was mapping. I limited my searching to Word document that I’d written entirely myself. The main functions in QGIS I used were pretty simple – I added primarily pictures and text to the map to convey the data I wanted to show. I did encounter a bizarre issue that occurred when attempt to scale certain images, where the images would scale vertically when I was adjusting them horizontally (and vice versa), but with some fiddling, I could usually get them back to normal and then scale them again. Barring that, deleting them and replacing them with an identical image always fixed the problem.
A glimpse into how things looked in QGIS around this point.
The largest challenge came when trying to add a legend to my map. Maybe I let myself get discouraged too easily, but the built-in function to add a legend was fairly unintuitive to the point where I really wasn’t making much headway at all in trying to get it to convey the information I wanted it to. Thus, I ended up caving, and I created the legend in my image editing software. I then added it as its own image.
The legend, in its lone glory.
Findings – I’ve dreamt about 12 out of the 25 states I mapped, or roughly half of them. – The number of pieces the average state was mentioned in: 4.84. – The number of pieces the average state I’ve dreamt about was mentioned in: 8.25. – The number of pieces the average state I’ve yet to dream was mentioned in: roughly 1.77. – In other words, states I’ve dreamt of appear in significantly more of my writing than those that I’ve yet to dream of. – I’ve mentioned my home state of New York with significantly more frequency than the next most mentioned state – over 4 times more. – The most common number of mentions was 1. – There doesn’t appear to be a strong correlational between the size of a state and the number of mentions it’s received: however, very generally, the very smallest states had some of the fewest mentions. – Similarly, there doesn’t seem to be a strong correlation between the size of a state and whether or not I’ve dreamt of it. However, I’ve dreamt about many of the largest states I mapped.
Closing Words I’m a little disappointed in myself for choosing such a self-centered project. It might have been more fitting to choose a more relevant or accessible topic than the one I chose. However, in the end, I got to experience QGIS for myself, I ended up with a map that I’m rather proud and fond of, and I enjoyed myself overall. I’m happy to say that I think this won’t be the last time I use QGIS.
After doing the readings (not to mention attending 3 other courses during the week), my understanding of Digital Humanities as its own distinct entity and field of study has certainly broadened. I still hold fast my initial impressions on it: that it innately marries aspects of traditional humanities with aspects of technology and the modern era, that it has an intrinsic sort of intertextuality to it, and that it’s a pervasive, yet subtle concept that exists in plain sight without people necessarily knowing that it is there (that is, many people engage with the digital humanities without even knowing it). However, after doing the readings I think I’ve come to a bit more a detailed understanding that I hope will only continue to grow.
Lisa Spiro’s “This is Why We Fight: Defining the Values of Digital Humanities” is the first piece I looked at with the idea of digital humanities consciously on my mind. It took me a little by surprise: Spiro doesn’t write very much about anything I could entirely view as a single, unifying force behind the subject. Rather, her writing seems to indicate a desire to outline was the digital humanities are more abstractly. That is, through her discussion, she provides information that when pieced together, forms an outline of what the digital humanities are, rather than beginning with simply citing a definition and then going from there. For instance, she writes that “the digital humanities encompasses fields such as librarianship in addition to humanities disciplines,” and that “[its] community promotes an ethos that embraces collaboration as essential to its work and mission.” While statement such as these explicitly characterize the digital humanities, they don’t outright define it, instead leaving one to independently interpret and piece together an individualized, yet guided and consistent idea of what the digital humanities could be.
A piece I read later on that also inspired me to a significant degree is “Digital Humanities: The Expanded Field,” by Lauren F. Klein and Matthew K. Gold. I read this after Spiro’s piece, which caused me to think about the relation between Spiro’s method of writing with Klein and Gold’s idea of a “big tent.” Klein and Gold outright state that “it can at times be difficult to determine with any specificity what, precisely, digital humanities work entails” within the first paragraph. Perhaps what spoke to me most from this piece was the idea that instead of “requiring that the tool-building work of an ImagePlot or a Bookworm, to name two recent contributions to that domain, speak directly to their objects of analysis,” digital humanities might “explore how the creation and deployment of such tools perform distinct but equally valuable functions.” I see a parallel between this and the idea of “show, don’t tell” – rather than just a requirement to have an explicit connection between a tool and a creation or other object, digital humanities allows for deeper and more varied examinations.
Part of the reason I submitted this rather later into the week was that I wanted to get more background knowledge on digital humanities from the other courses I’m taking in the digital humanities program. I won’t talk about each here, but I want to breifly bring into conversation a subject that Lisa Rhody discussed in her Methods of Text Analysis course: the idea that simplifying something or arbitrarily categorizing and grouping something for the sake of expedience may influence that which follows in its wake. In class, this idea was related more to sex and gender, and of course, I’m ironically grossly simplifying the idea, but I feel like it could be incredibly helpful to examining digital humanities in general.
To clarify, digital humanities doesn’t need a succinct, textbook definition. It’s an amalgamation of different ideas, backgrounds, and media. One could absolutely view it as a subject, either academic or conversational, but similar to, for example, feminism, formalism, and psychoanalysis, it can also serve as a lens to examine work under. Digital humanities as a lens probably has a significant of overlap with other lenses, but in a sense, all lenses have significant overlap with one another, and not simply because they are all lenses. An anthropocentric reading of a work could perhaps have a lot in common with a Marxist reading of the same work, or even other works, after all.
Need help with the Commons?
Email us at [email protected] so we can respond to your questions and requests. Please email from your CUNY email address if possible. Or visit our help site for more information: