
Earlier this week, I found myself thinking about pre-digital text mining a lot. Of course, the sorts of analysis we use tools like Google Ngram Book Viewer, Voyant, and JSTOR Labs Text Analyzer for have been in existence for far longer than the Internet, albeit in a different forms. Indeed, in my past, I’ve used much less advanced means to “mine” texts: during my junior and senior years of college, I spent quite a bit of time doing just that with Dante’s Divine Comedy, comparing different sections of it to one another, as well as to other texts. I’ve been told about and recommended Ngram and Voyant on many, many occasions in the past, but I’ve never had an excuse to explore them deeper. This project gave me the chance to explore not only those two, but also JSTOR Labs Text Analyzer.
I decided to perform a different experiment with each tool. While Voyant was described as the “easiest” of the tools, at first glance, Ngram drew my attention most due to the fact that it works of a predetermined corpus. This made me think about how reliable it could really be. At best, if one views this corpus as a “standard” of sorts, it could be used to compare multiple studies that used Ngram. However, I find myself wondering if information gained through Ngram could be potentially biased or skewed compared to information gained through other text mining tools that let you establish your own corpus.
In any case my first experiment wasn’t entirely in line with the project prompt, but I was curious, and I wanted to start somewhere. After reviewing Ngram’s info page, I decided to enter the names of a collection of 9 beings from different folklores and use the longest possible time range available to me (1500-2019). I made sure not to pick anything like “giant” due to the fact that “giant” is a word we use regularly with no attention paid to the associated creature. For consistency’s sake, I also didn’t pick any beings that are explicitly unique, such as gods.
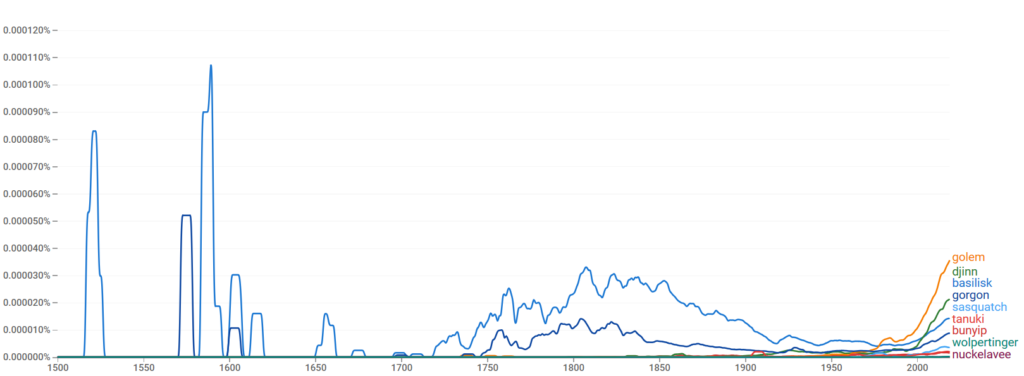
It gets a bit cluttered at points, but I think it presents some interesting results, especially about Ngram’s corpus. It’s immediately clear that the basilisk has the highest peak and overall mentions of any being in this experiment, and even in our time, is only surpassed by two other beings. We also have a pretty clear second place, with the gorgon, who is just below the basilisk, even today. With regards to today though, the golem and djinn went from being fairly obscure to being most and second most popular.
With regards to the former two, the basilisk and gorgon this may indicate a very strong bias in Ngram’s corpus in favor of Cantabrian-Roman (basilisk) and Greek (gorgon) – that is, Western – pre-20th-century mythological texts. Alternatively, it may indicate that writers during those times were using those words more often in figurative language and metaphor (this may be completely arbitrary), or that more editions of myths regarding those creatures came out during those times. With regards to with the latter two, the golem and djinn, respectively from Hebrew and Arabic folklore, have received much more media attention as time’s gone on due to the growth and popularity of the fantasy genre.
The other 5 beings, from most to least frequent in mentions, are respectively from North American, Japanese, Oceanic, Germanic, and Orcadian folklore. The Tanuki has its first uptick in popularity around 1900, or just before the death of Lafcadio Hearn, responsible for some of the first texts on Japanese culture available to a mainstream English-speaking audience. Additionally, while the wolpertinger (Germanic) and nuckelavee (Orcadian) are Western myths, they’re the two least popular, which doesn’t coincide with the apparent bias toward Western mythology. Perhaps it’s specifically a Greco-Roman bias? I would probably have to conduct a more in-depth study.
Moving on, I tried Voyant next. I was excited to upload documents and even experiment with my own writing, but I was surprised to see that I could upload images and even audio files. The first trial I gave it was trying to get it to upload the graph I posted a bit ago, and then a MIDI and an .m4a file I found in my downloads folder. I was saddened to see this:

But I pushed onward and found that Voyant certainly tried to mine the audio file I fed it. Of course, it spat it out as a bunch of garbled text, but I might make a foray into the realm of trying to get practical use out of getting a text miner to mine images and audio in the future. For the time being though, I decided to stick with something more conventional. I tossed it a .txt file with a single haiku on it that I had lying around for a proper test run, and then got to my real experiment. I uploaded a folder of between 40 and 60 Word documents containing poems (certain files contained more than one poem) I wrote since 2013 just to see what would happen, and I got the following lovely word map:

After doing so, I realized there wasn’t a lot of data to glean from this that wasn’t self-indulgent, and at points, personal. Apparently though, I really liked the word “dead” (note: there WAS a poem in there about wordplay regarding the word “dead.” it’s a lot more lighthearted than you’d think). My next, and for the time, final usage of Voyant involved A Pickle for the Knowing Ones by Timothy Dexter: using the “Split Pickle” view of the piece offered by this site, I compared the original text of the piece’s first folio to the site’s “translated” version. For those unaware, Dexter dropped out of school at a young age and was largely illiterate.
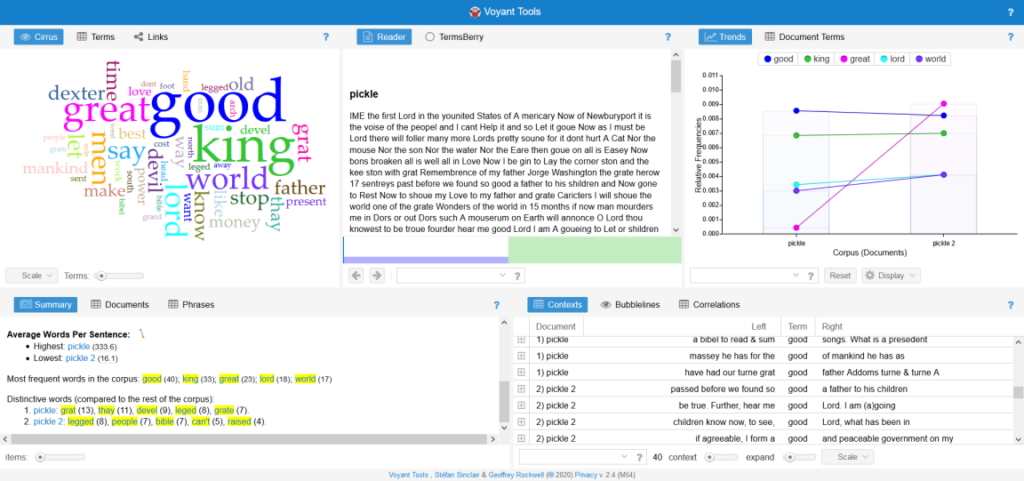
Of note, in the untranslated version, the average sentence length is 333.6 words. With this corpus, something of note is that all of the “distinctive words” in the original text are… not really words. The fact that the original has 8 instances of “leged” while the translated version has 8 instances of “legged” is a testament to this.
Finally, I experimented with JSTOR Labs Text Analyzer. Here, I decided to go with an essay I wrote on the overlap between architecture and the philosophy of architecture, traditional narrative, and video game narrative during my senior year of college, and I was pleasantly surprised to the point of being slightly unnerved with the result due to its accuracy.

There was a little less to experiment with on JSTOR, so I mostly left it at that. The number of related texts I was offered was certainly appealing though, and out of the three tools I experimented with, I think this text analyzer would be the one I would use for research, at the very least.

This entry is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International license.