In a paper published early last year in the Cornell Law Review entitled “A Computational Analysis of Constitutional Polarization”, law professors David E. Pozen, Eric L. Talley, Julian Nyarko describe their efforts to analyze remarks published in the US Congressional Record between 1873 and 2016. Their principle research question asks “whether and to what extent major political blocs in the United States have diverged in the ways they think and talk about the Constitution” (2019, 7). This praxis assignment undertakes a preliminary dissection of the project’s code and data made available by the authors. Through this dissection, it seeks to contribute toward (1) the development of a methodology of critique of computational and statistical techniques and (2) perhaps more importantly a way to ascertain the existence or not of confirmation bias.
While some of the underlying assumptions related to claims of “polarization” and “talking past each other” call for an assessment of the argument’s overall logic, Pozen, Tally, and Nyarko offer an impressively robust set of techniques and methodologies, which incorporate a number of self-critical considerations of their approach and strategies. Included in these considerations are: The attempt to correct problems in the data relating to misspellings and OCR failures; the use of five dictionaries containing varying levels of semantically coarse constitutional terms and n-grams; the use of several classifiers including the Multinomial Naive Bayes classifier, the Multilayer Perceptron classifier, the K-Neighbors classifier, the Gaussian Process classifier, the Decision Trees classifier, and the C-Support Vector Classification classifier; the use of three measures of classifier performance, including the standard rate of correct classification, the F1 measure, and the AUC-ROC measure; the generation of word frequencies and tag clouds; attempts to control for additional variables including the length of remarks; and the comparative analysis of congressional language with language in newspaper editorials.
Pozen, Tally, and Nyarko’s central finding is that “[r]elative to the early and mid-twentieth century, it has become substantially easier for an algorithmic classifier to predict, based solely on the semantic content of a constitutional utterance, whether a Republican/conservative or a Democrat/liberal is speaking” (2019, 4). “Beginning around 1980, our classifier thus finds it increasingly easy to predict the political party of a congressional speaker” (2019, 38). Thus according to the findings of the analysis “constitutional polarization…has exploded in Congress over the past four decades.” The link between predictability of ideology and polarization invites questions about the extent to which “ideologically coherent and distinct” unequivocally translates to “[d]ivision into two sharply contrasting groups or sets of opinions or beliefs” (2019, 34, 8).
Before examining the project’s use of the computational techniques, an overview follows of the provenance of the data. The data used in the analysis–which includes “13.5 million documents, comprising a total of 1.8 billion words spoken by 37,059 senators and representatives”–comes from a dataset prepared by Matthew Gentzkow (member of the department of Economics department at Stanford University and the private non-profit research institute National Bureau of Economic Research (NBER)), Jesse M. Shapiro (a member of the Economics department of Brown University and a member of NBER), and Matt Taddy (affiliated with Amazon) (2019, 18).
For the OCR scans of the print volumes of the Congressional Record, Gentzkow, Shapiro, and Taddy rely on HeinOnline, a commercial internet database service owned by William S. Hein & Co., Inc., based in Buffalo, New York, and which specializes in publishing legal materials. Gentzkow, Shapiro, and Taddy received funding from the Initiative on Global Markets and the Stigler Center at Chicago Booth, the National Science Foundation, the Brown University Population Studies and Training Center, and the Stanford Institute for Economic Policy Research (SIEPR), and resources provided by the University of Chicago Research Computing Center.
The data provided by Pozen, Tally, and Nyarko consists of a 1.1 GB binary file containing the word embeddings used for the classifier. Additionally, there is a 0.4 MB zip file containing a CSV file for each of the 72 congressional sessions containing the frequencies for the n-grams used for the tag clouds.
Pozen, Tally, and Nyarko apply a number of preprocessing transformations to the corpus, including the creation of word embeddings as a way to correct for misspellings, miscodings, and OCR issues. One transformation the authors did not undertake is the removal of stop words due to the fact that a number of constitutional phrases contain stop words. The following table presents a summary included in their report of the breakdown of the corpus.
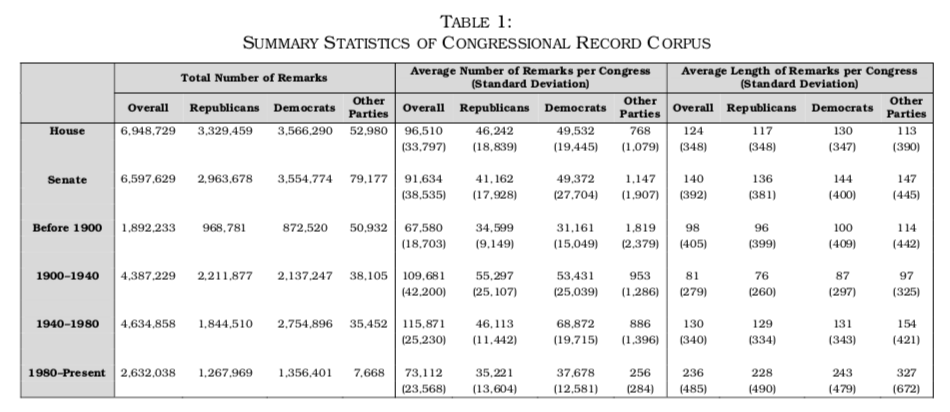
(Click on Image to Enlarge)
While the Python and R code provided by the authors does not run without modification (the Python code is saved to files as Jupyter notebook code blocks), there is enough code that together with the methodology described in the project’s paper enables the discernment of the processing paths and implementation of algorithms. The speeches are vectorized in a pipeline as part of the process of training the models. In terms of predicting the party (Republican vs. Democrat) and ideology (Conservative vs. Liberal), the project uses scikit-learn’s multinomial naïve Bayes classifier as its primary classifier and a cross validation predictor that follows a 5-fold cross validation strategy. The data is split into 80% training data and 20% testing data. The R code is used to create the line charts and scatter plots from the results of the classifications utilize ggplot2 and the cowplot add-on.
The project includes the application of a number of additional computational techniques and secondary findings, including:
- that polarization has grown faster in constitutional discourse than in nonconstitutional discourse;
- that conservative-leaning speakers have driven this trend;
- that members of Congress whose political party does not control the presidency or their own chamber are significantly more likely to invoke the Constitution in some, but not all, contexts; and
- that contemporary conservative legislators have developed an especially coherent constitutional vocabulary, with which they have come to “own” not only terms associated with the document’s original meaning but also terms associated with textual provisions such as the First Amendment. (2019, 1)
Further evaluation of the project’s code would be needed in order to complete an assessment of the techniques and methodologies underlying these secondary findings.
Conclusion
Through a preliminary evaluation of the code, data, and computational techniques underlying “A Computational Analysis of Constitutional Polarization”, this praxis assignment has attempted a critical assessment of the methodologies Pozen, Talley, Nyarko leverage in their research. While the ample use of self-critical analysis argues against confirmation bias, there would nevertheless appear to be weakness in linking “idealogical coherence” with the claim of “talking past each other”. As one of a number of examples of further research, Pozen, Tally, and Nyarko suggest the application of computational techniques to validate or invalidate the argument made by Aziz Rana that “the culture of ‘constitutional veneration’ is a relatively recent phenomenon bound up with the Cold War effort to justify American imperial ambitions” (2019, 68).
Works Cited
Gentzkow, Matthew, Jesse M. Shapiro, and Matt Taddy. 2018. Congressional Record for the 43rd-114th Congresses: Parsed Speeches and Phrase Counts. Palo Alto, CA: Stanford Libraries [distributor], 2018-01-16. https://data.stanford.edu/congress_text
Pozen, David E., Eric L. Talley, Julian Nyarko. 2019. “A Computational Analysis of Constitutional Polarization” In Cornell Law Review, Vol. 105, pp. 1-84, 2019. SSRN: https://ssrn.com/abstract=3351339.