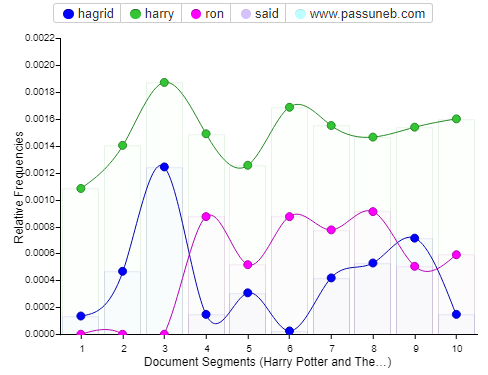
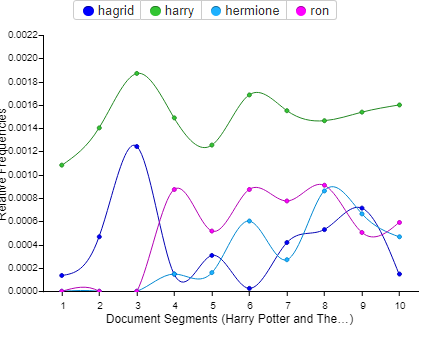
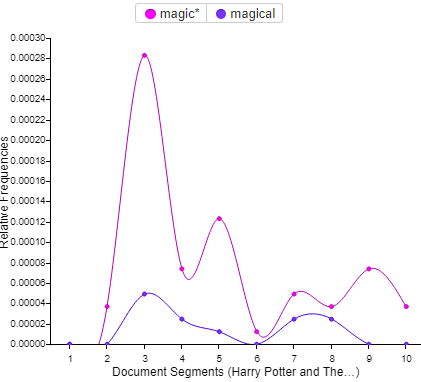
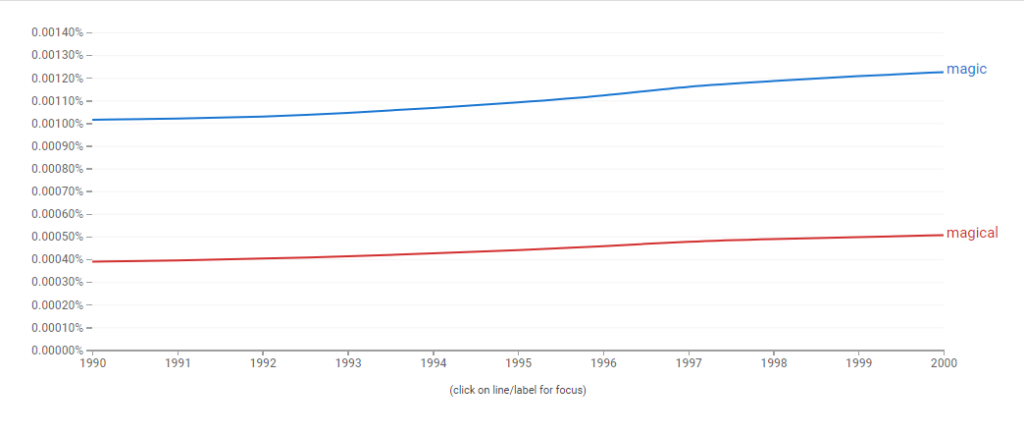
Thoughts on Class- When I first started looking into possible majors to start my graduate work I decided I wanted to take a risk. Sure I could of continued on my path of English Lit and Journalism but a part of me (very strong part of me) was not satisfied with what I was doing in regards to both of these subject areas. I wanted to explore a new territory, one that was completely foreign to me. One that I know would help me develop new skills but also challenge me along the way. Somewhere along my research trying to find a subject that would do that for me I stumbled upon Digital Humanities. Truth be told I had to google the definition of this field cause I had never heard of it before. The search results that came up both confused and intrigued me. I didn’t know what this subject entailed but from what I could see it included a little bit of everything. From there I took a gamble and decided to apply for the Masters DH program at the Graduate Center. When I first learned of my acceptance I was elated but soon a feeling of panic also set in. I was coming into this with no prior experience, although experience wasn’t needed the egoist in me didn’t want to come off like I didn’t know what I was doing. But I didn’t know what I was doing . Every week in class I listened to my peers wise words and insight and I sat there not knowing what to say. I felt intimidated but also so amazed by the thoughts you guys came up with. This class was mentally stimulating in so many ways. Professor Gold did a great job in allowing us students have an open space to discuss and converse. I soon realized that I wanted to navigate this class the best way I felt I could. I wanted to listen, learn and absorb. If I didn’t have the right words to try to convey what I wanted to I gladly listened to my peers do it. Maybe in the end I do have some regrets about not participating that much but I’m happy with how this semester went. Thank you to all of you guys for being such a great class.
Final Project- As the semester was nearing its end I knew it was time for me to start thinking of a topic for a final project. As I racked my brain for ideas on what I wanted to do my project on I unfortunately kept hitting dead ends. I initially wanted to do something based off of social media and how I can somehow come up with a way to create filters on platforms to help separate factual information from posts that are put up to spread lies. I know some sites already do this but I wanted to create an upgraded version. However this idea didn’t end up going anywhere as I quickly overwhelmed myself with the prospects of what I needed to do to complete this project. I had no idea where to start or how I would expand on it. So in a last minute decision I decided to start fresh and look at the prompt to get a new idea. Although this project would of been great practice I figured I wasn’t ready to dive into grant work just yet. I’m keeping the social media project in the back of my head for the future but for my first semester I wanted to go with the seminar paper option instead. Labeled under pedagogy the seminar paper I chose to go with involves creating a syllabus for a hypothetical DH class. I immediately gravitated towards this as I knew it would allow me to be creative. As a first year DH student it may come off bold and pompous to feel as though I have authority over what should be taught in a DH class but in my opinion I just saw this as an opportunity to add to the conversation that is already being had in DH. What can be done to improve this field? What should be allowed in DH? How far should it expand? I wanted to showcase what I thought was most pertinent in this field and how I feel a class of this subject area should function. In my paper I label my class as a quasi workshop setting. Most of class time will be spent doing hands on projects such as text mining movie scripts and books and using Google Earth to track the location of their parents’ hometown like Mayukh Sen did in “”Dividing Lines. Mapping platforms like Google Earth have the legacies of colonialism programmed into them“. These are just some examples but students will use what they know from readings and class discussions and apply it to physical work. Some of my projects are directly inspired by ones we had to create for this class, though I did make a few minor tweaks. Along with projects I also added a blog post element. Over the course of this class I thoroughly enjoyed both writing and reading everyone’s posts on Cuny Commons. I felt that they were a great way to express ourselves in a class setting without having to be too formal. Blogs for my hypothetical class were created for students to communicate their thoughts along the semester. As an instructor I want to know what’s going on in my students minds, I want to know if they’re engaged with the material. The blog posts and the projects will make up for most of their grade and participation counts for 10%. I would ideally want student to participate in class but I know from my own personal experience that doing so is not always easy. The discussions we have in class will revolve around reading material I have provided. Some texts were taken from Prof. Gold’s syllabus as I felt they worked well with certain subjects I wanted to teach. Others were taken from other DH syllabi I found on the web. I looked into each one and decided which worked the best. Additionally I also added a few articles I had found on my own that I felt added extra food for thought. Based off of the readings and projects I crafted the two final project options. One will be a 10 page paper based on a specific term or debate that came up in the readings or a creative project that features students utilizing a computerized DH tool to expand upon a in class project. This will also include a 5 page paper explaining their process and any problems they encountered. In all I wanted my syllabus to mix in traditional elements of a DH class with an updated twist. When researching DH syllabi I’ve noticed many are densely populated with reading material, most of which I felt could be done without. Maybe I feel this way because I geared my syllabus towards a undergraduate/elective level but I personally believe students will be more captivated by this field if they were given more opportunity in class to perform rather than read. I think this intro course gave us a pretty good balance of assignments and readings. For my own class I simply wish to expand on it.