

As a former English major I’ve read and analyzed my fair share of texts. Everything from mid century novels to Shakespearean plays pretty much encapsulated four years of my life. Although I appreciate the literary enrichment they have provided me they did not entice my literary curiosity as much as the Harry Potter series, in particular the first book. I guess I’m favoring more sentimental value over content value when I make this statement but much like the first praxis assignment I wanted to work with something that was of genuine interest to me and when I think of a text that does that nothing comes to mind more than “Harry Potter and the Sorcerer’s Stone”. I can read this book over hundred times and still feel like I’m being directly transported into a world of magic- a key term that I will end up exploring while text mining.
***Now before I get into my findings I want to put a disclaimer here about the author that created this book***- Unfortunately in recent years J.K Rowling has been known less for the books she created and more for her controversial and offhand remarks regarding trans individuals in particular trans women. I do not agree with her way of thinking when it comes to this topic at all and find her thoughts on the matter to be appalling and unacceptable. However in our last class we touched upon this idea of separating art from the artist in regards to their work. After giving this much thought I felt it was okay to go on using a Harry Potter book as the focus of my project as I don’t believe the legacy of these treasured tales should be sullied by the gross remarks of the author. With that being said I apologize to anyone I may offend, it is not my intention to do so. I come in with completely innocent intentions.
In looking at the tools that were suggested to us I decided to start things off easy and try my hand at using Voyant. The logistics of this tool is fairly simple and to the point. The homepage starts off on a box where you can input text, url’s or upload a downloaded file. I already have a full e-book version of “Harry Potter and the Sorcerer’s Stone” on my laptop that I downloaded from a website called passuneb.com- an e-learning platform that provides free educational resources to primary and secondary students. Although I am thankful for the easy accessibility and zero dollar charge that came with the downloaded e-book I was a bit irked by what I can only describe as water marks on each page.

(These two were on every page)

The repetitiveness of the website’s name ended up getting added to my generated corpus and mixed in with my results. I couldn’t find a way to omit it from my results but luckily I was able to take it out in my line graph showcasing document segments.

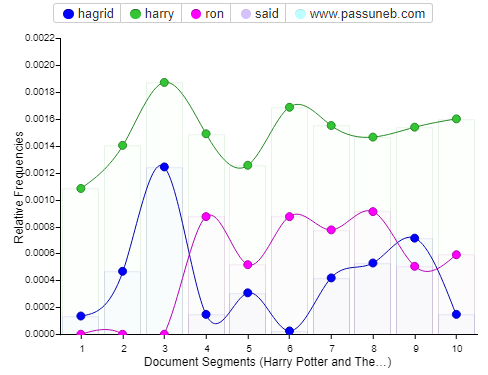
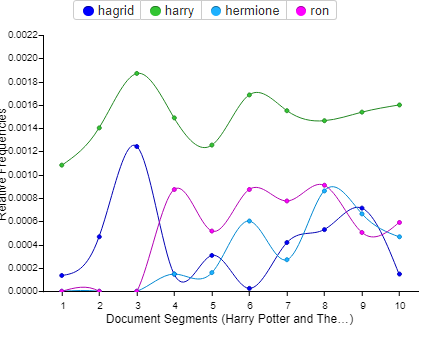
My cirrus word cloud visualizes www.passuneb.com in a larger font because the term appears 452 times, that’s more than the appearance of the names of most of the characters. In addition the line graph that Voyant came up with also featured the website’s name as well as the word said, both of which were taken out by me as I didn’t think they were relevant in what I wanted to see. Instead I wanted to focus more on the central characters names and how many times they appear in the novel. Voyant pointed out that the names Harry, Ron and Hagrid pop up the most with Harry having a total of 1,214, Ron with 410 and Hagrid with 336. From here I started playing around with the tool myself. I wanted to add Hermione to my document segment graph as she is a vital character to the novel. Her name comes up 258 times putting her right behind Hagrid in terms of character names. Adding her into the graph was easy as Voyant has a feature right underneath the graph where you can input the words you want to visualize. You can input multiple words or just leave it as one. Each character name was differentiated into a different color with the key above the map to show which color coincides with each name. Voyant also has a display feature which allows the user to add labels or change the style of mapping. For example instead of a line graph one can do a bar graph, however I felt the line graph was the most clear way to show the results.
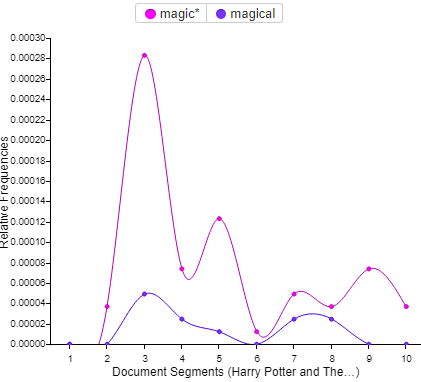
After looking into the character names I was interested to see what would come up if I looked at how many times a particular word or phrase appeared in the novel. The words I chose to go with were magic and magical- it only makes sense for a book that’s based off of the existence of magic. In my findings the word magic came up 48 times while magical came up 11. I was a bit shocked the results were lower than expected but perhaps that’s my mind playing tricks on me as I must of convinced myself that the words came up more than they actually did each time I read the book. I guess this is why tools like this are so important when it comes to research, the human mind is not one hundred percent accurate at all times.
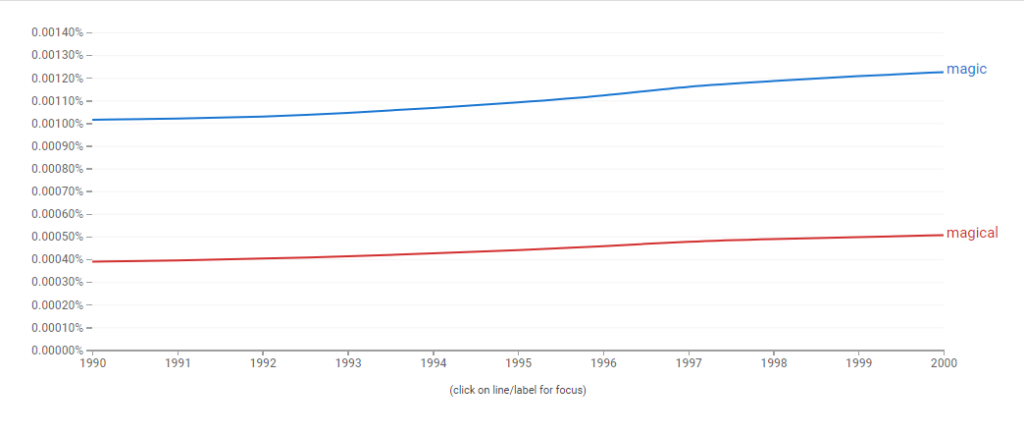
Nonetheless I still wanted to experiment more with these words so I decided to shift my attention to Google Ngram. In the search bar I input the words magic and magical and narrowed down the year search from 1990-2000. The words saw an increase starting from 1997 towards 2000, “Harry Potter and the Sorcerer’s Stone” was first published in June of 1997. I’d like to believe the introduction of this enchanting series jumpstarted the increase.
In conclusion I have mixed emotions about this first step I have taken into text mining. It was fascinating to say the least to be presented with these findings in less than a minute but I feel like the tools still have a few flaws. In Voyant’s case I fully understand why the they chose to put the website’s name in the results as it is featured in the text and is used often. Voyant did it’s job and emphasized it in it’s finding. However for aesthetic purposes I wanted to solely visualize specific things in my results i.e the character’s names and the word magic/magical and wish the website wasn’t as spotlighted. If I’m missing something and there is a way to take a word out of the cirrus then please let me know in the comments. As for Google Ngram, I felt the tool was easy enough to use but I was a bit disappointed with the lack of information that was provided to me. In other words I wish there was more to play around with on the site, perhaps features that allow you to change the physical appearance of the map other than the smoothing tool. Complaints aside this exercise has definitely opened me up to a world of research that I have not had the chance to experience before. I look forward to working with these tools some more in the future.

This entry is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International license.
Faaiha, your post was a really satisfying read, I enjoyed learning about your experience. You found a silver-lining and your steps to your text analysis project feels viable and pedagogical. I also value your transparency about the dissonance that came with the analysis of this text for the reasons you shared.
(**Faihaa – my sincere apologies for misspelling!)
Thank you Asma! I’m glad you were able to enjoy reading about my first experience text mining