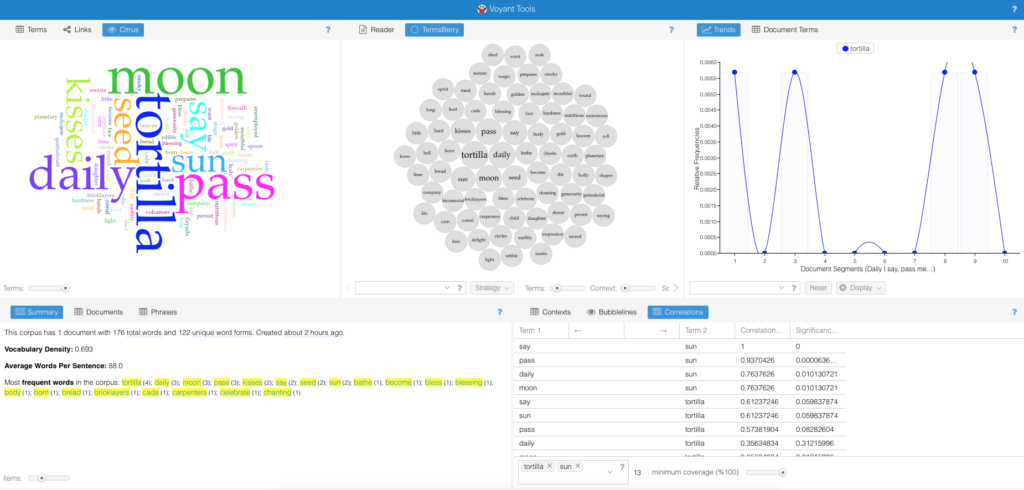
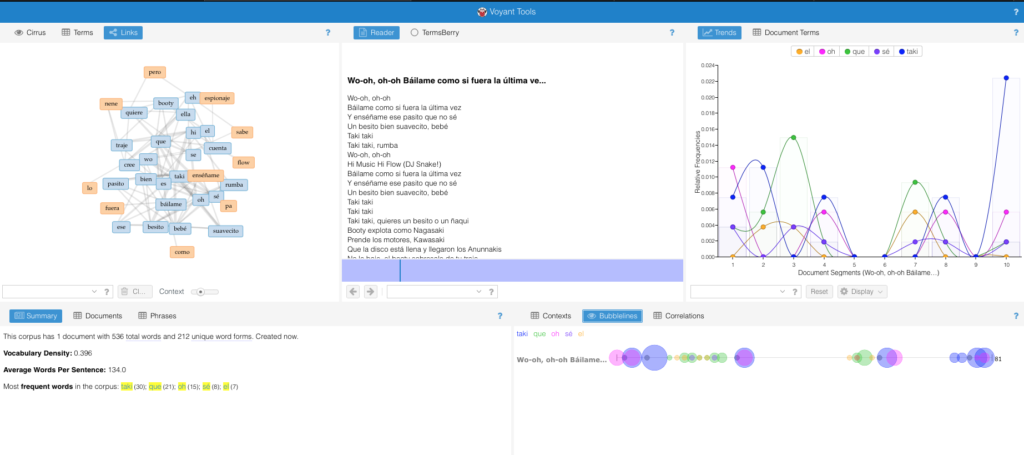
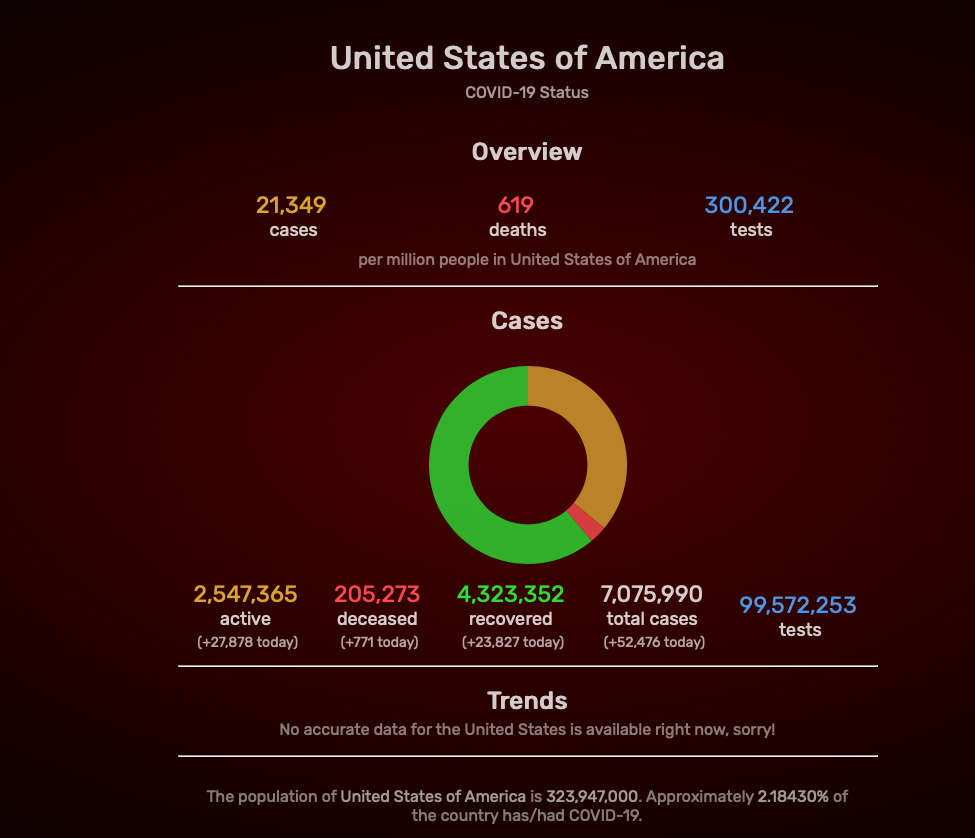
For my final project, I proposed an extension for the text analysis tool suite, Voyant. During my first experience with this tool, I came across the need for a mixed text analyzer. Since I couldn’t find one, or at least one that was open source, I decided to contact Voyant and see if they would be interested in improving their already great device.
After speaking with Geoffrey Rockwell, one of the creators, I became intimated by the thought of the amount of work the would go behind making such an extension. I was convinced that it would be a simple tweak to their tokenizer, but the extension would ultimately need an experienced Javascript programmer and possibly a linguistic scholar. Rockwell pointed out that the way around analyzing mixed text is to first separate the corpus into two (or more depending on how many languages present in the corpus) and then import the texts individually to Voyant. I was not too thrilled with that idea. He told me about Voyant‘s Spyral which was design with digital humanist in mind. After receiving various suggestions on different extensions, the team at Voyant decided to construct a tool that would tailor the explorer’s newfound data based on Javascript coding. By importing both text and code, a user can essentially make the different extensions work to accommodate the user’s needs. Therefore, he suggested I could either learn Javascript or ask for help from a programmer to tweak the tokenizer myself and ask it to recognize and categorize the mixed text. I didn’t want to do that either.
I proposed having an extension that would work alongside the other tools like Mandala, and Termberry to identify and classify the languages, determine the relationships between each other, and to compute how much of each language was used in the entire document. I sent over a sketch as well as a list of a few of the Voyant tools that could be modified to fit this extension.
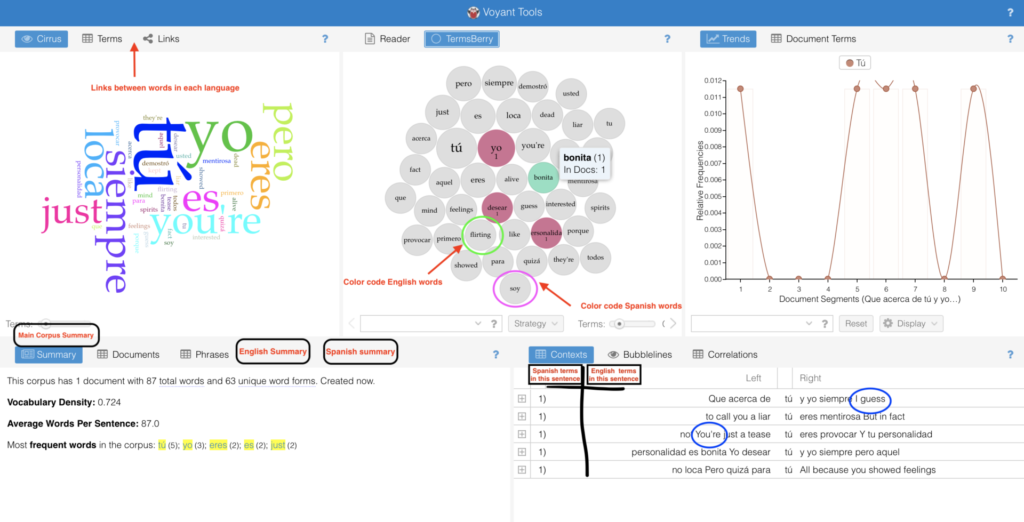
What I didn’t realize is that even though I write bilingually most of the time (not just informally through mobile text messages and social media posts, but also when writing scripted television and other forms of storytelling), the style of writing is not widely accepted as formal or as style scholars are interested in analyzing. After researching, I found not digital humanists, but prominently analysis in customer service and marketing would be interested in this tool. This is because the writings they investigate are informal, digital consumer reviews, and social posts which tend to be bilingual.
I argued for the benefits in the humanities including literary scholars analyzing bilingual and multilingual poems, to more social linguists that would like to investigate the cultural influence behind these pieces as well the usage of syntax in such texts. However, after finding an experiment on such a tool done back in 2015, I understood that a more practical use for this tool might be in the pedagogical sector. Professor Siu Cheung Kong along with his colleges in Hong Kong, China created a plug-in on Moodle, an e-learning course builder for educators. The plug-in would allow educators to analyze the works of ESL and TSEOL students.
After the research I had a difficult time completing the last two section of this paper: work plan and dissamination. Other than an HTML and C++ lesson in high school, I never had any training in building any digital tool. I knew I needed help but I didn’t know where to start. I was sure of what I wanted the tool to do and how it must work seamlessly with Voyant, but other than needing Javascript, I was lost. I didn’t know the timeframe nor the work behind creating something like this.
Needless to say, I wanted to challenge myself and I did. I could have asked for more guidance in both the construction of this tool and the writing of this final paper. I needlessly struggled alone even after learning how much time and human power it takes to construct any digital humanities project, especially when the “digital” part is not your strong suit!