Last month I took a seasonal dive into vampire folklore and its appearance in literature, film, and video games, thinking about the vampire archetype as it correlates to power, illness/medicine, and of course, im/mortality. (“Seasonal” in this case meaning both Halloween and political season.) As a result of having vampires on the brain, I did a quick analysis of the different spelling variations of the word vampire that I was familiar with appear in English literature: vampyr, vampyre, and vampire, to see the trends in Google’s Ngram tool. I didn’t assume that I would have such meaningful results.
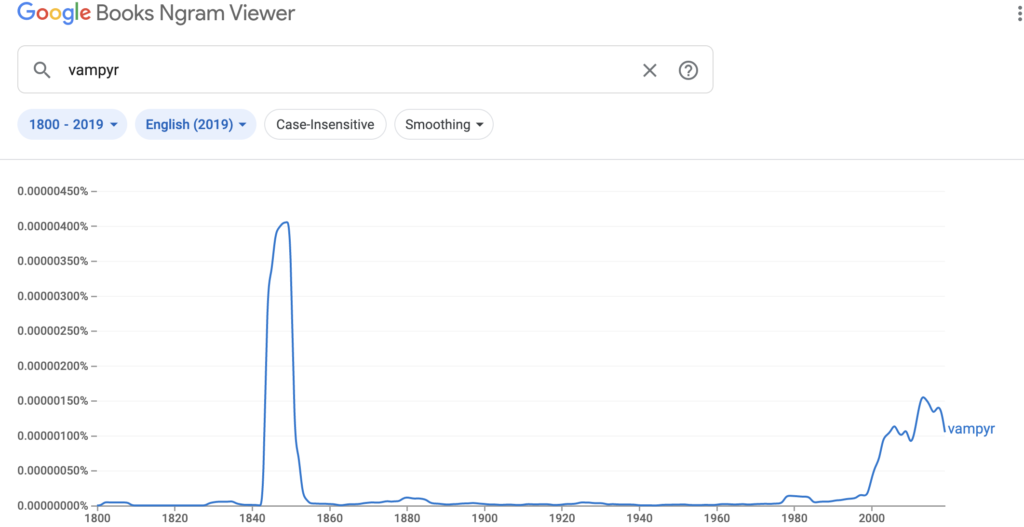
“Vampyr” alone has a clear bump in published words beginning in the late 1830s which correlates to literature about the opera Der Vampyr, and sometimes to its source material, a stage play with Der Vampyr in the title as well from a similar period. It also increases in popularity as the overall trend in vampire content increases in the late 20th century, though after reading a bit about Der Vampyr, I wonder if there’s a correlation with this spelling, and a BBC miniseries based on the opera in the 90s. Google’s tools largely return novels with “Vampyr” in their title as the source of the trend, but if I were researching the term further I’d want to know if the authors had seen the miniseries and if that influenced their stylistic spelling choice.
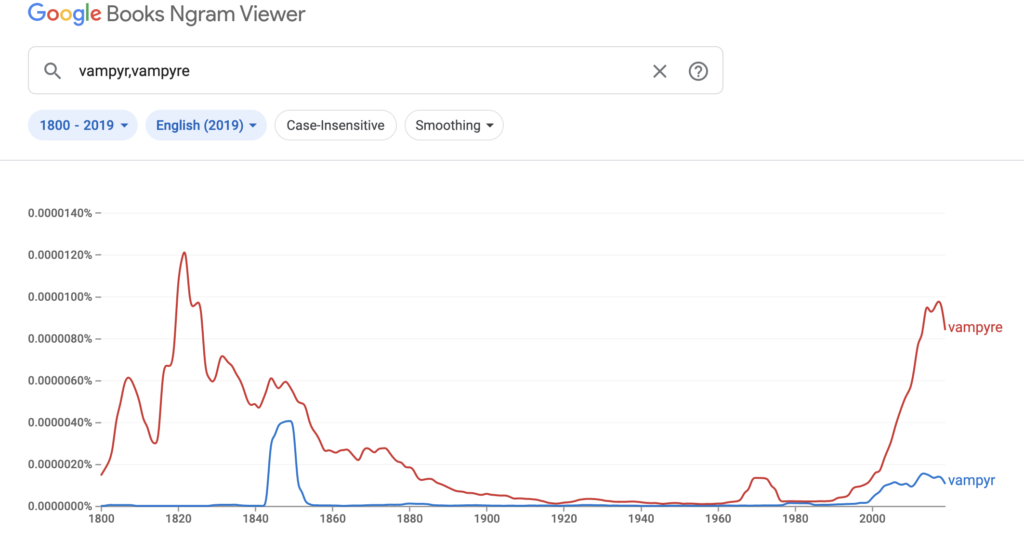
The Ngram for “Vampyre” was the richest graph I pulled as the first bump in the timeline correlates with the short story by John Polidori, The Vampyre: A Tale, published in 1819. While I was familiar with the name, I was not aware of its place in (forgive me) the vampire chronicle: Wikipedia’s entry on this revealed that not only is this considered to be (Along with Bram Stoker’s Dracula, later in the century) one of the first of the vampire stories as we know them today, but that it was also the source of the source material for Der Vampyr, the opera of the previous Ngram. More trivia: Polidori’s Vampyre was the “winner” in a contest between Percy Bysshe Shelley, Mary Shelley, Polidori, and Lord Byron (who was credited with writing The Vampyre due to an attribution error for a while). Another famous work submitted to this contest was Frankenstein! Also of note from further Wikipedia diving: Byron references vampires in at least one of his poems from the 1810s as well and to be the inspiration for Polidori’s Vampyre himself, Lord Ruthven!! The literary tea from this exercise!
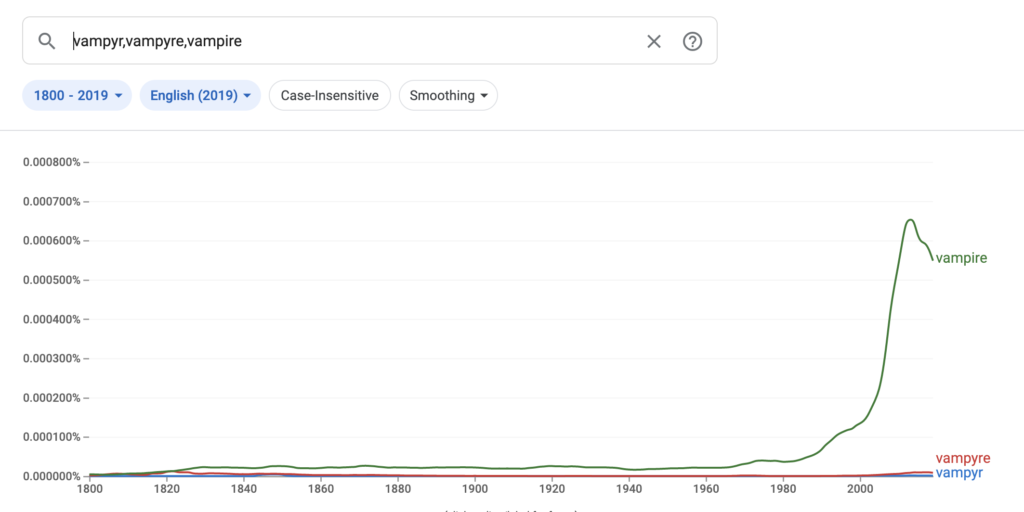
“Vampire” on the other hand, has a clear upward trending line that correlates with my understanding of the romantic vampire trope’s ascendance, and when compared, the standard modern English spelling eclipses the other two starting in the 80s. Without any further research I wonder if this correlates with the publication of Anne Rice’s series and also with the rise of another pandemic, or both. Unfortunately I wasn’t able to figure out how to hone into that specific decade, though in the search results Google gave me in the time range chosen by the tool, Rice was the most prevalent author. Many of the other books were anthologies, signifying enough content created by then to do so.
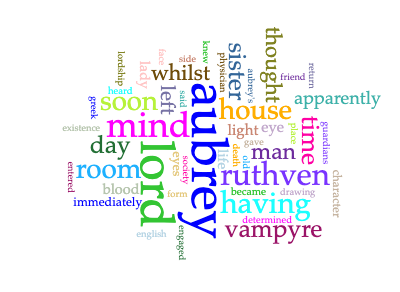
Bram Stoker’s Dracula is another small bump in the early 20th century, which inspired me to do a quick Voyant comparison between the Dracula text and the Vampyr text, as both are available to the public. This leads me to my second terrifying text analysis, via word clouds.
Dracula Word CloudThe Vampyr word cloud
There were not many surprises except for one: how infrequently the word “blood” appears, since one assumes hematophagy is one of the defining characteristics of the archetype, in the way that it is one of the defining characteristics of a mosquito. Given that my exposure to the vampire archetype is firmly rooted in the 20/21st century, my bias on this characteristic may be overly influenced by my exposure to the vampire of film and television, where themes of the same genre may be weighted differently due to the way the reader/viewer perceives them. All speculative, because the text analysis tools alone cannot give me direct insight into film and television trends, but directionally it is an interesting question to ask.
I was surprised to find that text analysis, using the simplest tools I found, created such a rich study of a subject by simply inquiring. I initially had overwhelmed myself with the concept of text analysis, but I was relieved to find that with a bit of tinkering, the tools invoked a natural sense of curiosity and play, leading to further analysis. (Apologies to all for my tardiness as a result!) As an unintended result of this project, I am inspired to read both of these 19th century works of the early romantic vampire canon.
From the moment the text analysis assignment was mentioned, I knew I wanted to do something with transcripts from the TV series Buffy the Vampire Slayer (seven seasons airing from March 10, 1997, to May 20, 2003). I had no idea what I wanted to examine or any question I might want to answer, but it’s a show I love and have seen many times, and I figured it would just be fun.
Text Gathering
I decided to do a “bag of words” comparison in Voyant using the Cirrus word cloud tool, and I originally expected to use each of the seven season finale episodes as my texts, assuming that a season finale encapsulates the overall themes from the entire season and I might be able to identify some kind of series-wide arch. But some finales were two-parters, so the amount of text being compared across seasons wouldn’t be the same, which I thought could be a problem. Inspired by our class conversation last week as we tried to answer the question “What is text?,” I realized there are several episodes of BTVS that play with some of the concepts we were discussing. So I decided to play around with the transcripts from select episodes instead to see what I might learn. I had wanted to take all of my transcripts from the same source, but this proved problematic as not every archive had complete transcripts for every episode. For the first two episodes I chose, I got the transcribed text from angelfire.com. For the latter two episodes I chose, I got the transcribed text from transcripts.foreverdreaming.org. None of these are official transcripts.
I initially copied the text for each episode into a word document, as I wanted to make sure there wasn’t any hidden metadata creeping into the text that might distort my visualizations/analyses. Some of the transcripts including stuff like “ACT I” or “Commercial Break,” both of which I removed. I was initially worried about the scene/stage directions being highly subjective as they were written by different fans (and not from the original scripts used in production) and also about the “Name: dialogue” format for the lines. But I figured most of this type of text also exists in other narratives like books when the author is setting scenes and defining who is speaking. However, when I put in the text for each episode, all of my word clouds were primarily just the names of the main characters and the most prominent secondary characters in each episode, which didn’t really seem very interesting in terms of analysis potential. So I then went back into each of the transcripts and removed the names of the four main characters (Buff, Willow, Xander, and Giles) as well as any of the other characters who are prominent in the series or were just prominent in that episode (e.g., Ms. Calendar, Angel, Spike, Anya, Oz, Tara, Dawn, Riley, Wesley, Jonathan, etc.). I also expanded the word clouds to include the top 155 words from each episode.
I Robot, You Jane
The first episode I chose is “I Robot, You Jane” (season 1, episode 8) in which a demon, Moloch the Corrupter, that had been imprisoned inside a book is released into the internet when the book is scanned as part of a digital archiving initiative at the school. Rupert Giles, the school librarian, gets into an argument with the computer science teacher Ms. Calendar, who is leading the initiative, at the beginning of the project:
Ms. Calendar: Oh, I know, our ways are strange to you, but soon you will join us in the 20th century. With three whole years to spare! (grins)
Giles: (smugly) Ms. Calendar, I’m sure your computer science class is fascinating, but I happen to believe that one can survive in modern society without being a slave to the, um, idiot box.
Ms. Calendar: (annoyed) That’s TV. The idiot box is TV. This (indicates a computer) is the good box!
Giles: I still prefer a good book.
Fritz: (self-righteously) The printed page is obsolete. (stands up) Information isn’t bound up anymore. It’s an entity. The only reality is virtual. If you’re not jacked in, you’re not alive. (grabs his books and leaves)
Ms. Calendar: Thank you, Fritz, for making us all sound like crazy people. (to Giles) Fritz, Fritz comes on a little strong, but he does have a point. You know, for the last two years more e-mail was sent than regular mail.
Giles: Oh…
Ms. Calendar: More digitized information went across phone lines than conversation.
Giles: That is a fact that I regard with genuine horror.
Ms. Calendar: Oh, you are a big snob. You, you think that knowledge should be kept in these carefully guarded repositories where only a handful of white guys can get at it.
Giles: Nonsense! I simply don’t adhere to a, a knee-jerk assumption that because something is new, it’s better.
Ms. Calendar: This isn’t a fad, Rupert! We are creating a new society here.
Giles: A society in which human interaction is all but obsolete? In which people can be completely manipulated by technology, well, well… Thank you, I’ll pass.
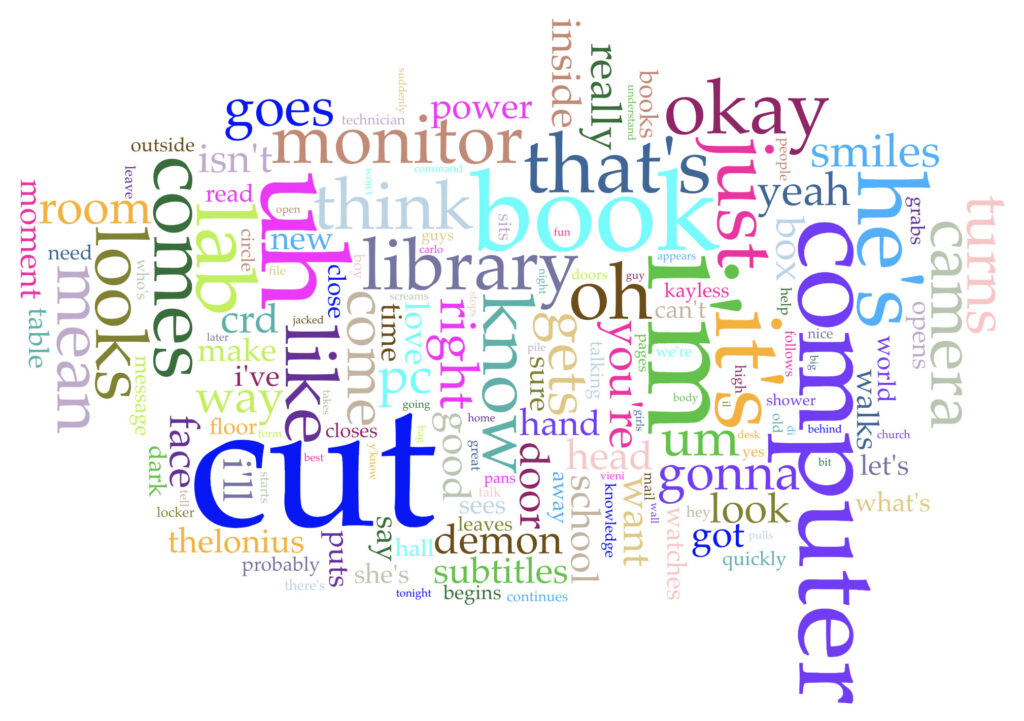
The episode aired in 1997, and Giles’s character is generally portrayed as a technophobe throughout the series. His latter argument against technological innovation as good only because of its newness and against technology being necessarily the direction of “progress” reminds me of Johanna Drucker’s “Pixel Dust: Illusions of Innovation in Scholarly Publishing.” And Ms. Calendar is clearly trying to promote technology and digital archives as means to open access and inclusion. Does any of this come through in the word cloud? I think a little bit, with computer and book coming through as two of the highest used words (at 39 and 37, respectively). Cut is the most used word at 93, but I’m fairly sure that is because of stage directions.
Voyant Cirrus word cloud for BTVS season 1, episode 8.
Earshot
The second episode I chose is “Earshot” (season 3, episode 18). In this episode Buffy is fighting some demons, per usual, but something goes wrong when some bodily fluid from a demon is absorbed through her hand. She is infected with “an aspect of the demon,” which turns out to be an ability to hear other people’s thoughts. At first this is exciting as Buffy hears what other people are thinking of her and finds out interesting secrets people are keeping; however, the power grows and grows to the point at which it is driving her mad because she is hearing everything from everyone and cannot distinguish any of it. I thought of this episode when we were debating in class whether everything could be text and an example given was everything that people say, whether or not it is recorded or preserved. As we touched on text being understood through symbols, I thought words that we see only in our minds but do not share, either written or aloud, could also be text. This episode also felt like an apt analogy to what it might feel like for a human mind to analyze text on the same scale as a computer. What does this word cloud show? Looks, look, and looking are all very prominent, as are thoughts and demon. Cut again is very high, but this again I think is attributable to the stage directions.
Voyant Cirrus word cloud for BTVS season 3, episode 18.
Hush
The third episode I chose is “Hush” (season 4, episode 10). In this episode, the town of Sunnydale is the setting for a gristly fairy tale, where the Gentlemen come in and silence everyone so that nobody can scream as they harvest the requisite number of hearts to terrorize humanity another day. So here we have an episode (and text) that is essentially quiet, with communication limited to succinct phrases and crude pictures easily written/drawn on portable white boards and the nonverbal—body language and pantomime. Are these forms of communication text? I’m inclined to say yes as ultimately an entire storyline is conveyed to the audience just as it is for any other episode of the show. Given that this episode has the least amount of dialogue and relies the most on stage directions, which were written by a fan and are not from the original script, I’m guessing this word cloud says more about the word preferences of the specific person who wrote this transcript more so than any of the other word clouds (though likely the original script would do the same of those writers, and now I’m wondering whether my assumption of a single author is even remotely accurate as each episode in the show and across the series would have had multiple and at times different authors). Gentlemen/Gentleman are both relatively dominant in this word cloud, as well as lackey/lackeys (who assist the Gentlemen). Looks is also high up there again, and picture and talk seem to be about the same size, though I think talk is present here because of its absence, especially as can’t is also very prominent (“Can’t even talk/can’t even cry” is part of the Gentlemen’s grim fairy tale rhyme).
Voyant Cirrus word cloud for BTVS season 4, episode 10.
Once More, with Feeling
The last episode I chose is “Once More, with Feeling” (season 6, episode 7). The musical episode! This time all of Sunnydale is under the spell of a demon who forces everyone to communicate through song and dance. It’s a feast for the eyes and the ears. Someone in class had discussed sheet music as text, and certainly song lyrics are text. (Would choreography also count as text?) Going off of that, then, this episode would contain two texts (three?) actually, the music as well as the lyrics. How do these texts “speak” with and inform one another? How is the message conveyed differently? I’m not sure this word cloud can really measure that as it only represents the lyrical text and not the musical text. Sweet is by far the most used word (65); looks and looking feature prominently again (are these stage directions or spoken?). Song, singing, and dancing are also high up there, and I can see other music-related terms like musical, refrain, sing, sings, dances, music, rock. I’m happy to see that bunnies also makes the cut for this cloud (because “It must be BUNNIES!”).
Voyant Cirrus word cloud for BTVS season 6, episode 7.
Future Text Mining
What did I learn here? I’m not entirely sure. Also, I had all of my Voyant tabs open for a while, and I noticed that the layout of the word clouds kept shifting (like the stairs at Hogwarts). In checking my word cloud links, the displays have even changed from the versions I took sceenshots of (WHY?). This makes me even more confused about how Voyant determines the layout of this particular visualization tool and how useful it is to compare different words clouds against each other. Going forward I’d be curious to know how these clouds might look differently if I were working from the finalized scripts used for producing each episode. I’m also curious to dig a little deeper into the difference between stage directions and spoken dialogue. Do we need to distinguish them? It seems like they both ultimately work together to tell the story of each episode. Are there visual cues in the final episodes that are not represented in the stage directions? What does that say about translating text into images and vice versa?
As I mentioned on Wednesday, I went into this project thinking I had a hypothesis in mind and was determined to make a discovery. But I ended up spending most of this project just exploring the functionality of both Voyant and Google Ngram, and wasn’t able to really make any monumental revelations. I was even wracking my brain to come up with sample text that would reveal something, but struggled to think up anything specific. I ended up browsing the public domain and pulled up Louisa May Alcott’s, Little Women, just to get started with something. But exploring is good – and I enjoyed getting familiar with these text analysis tools.
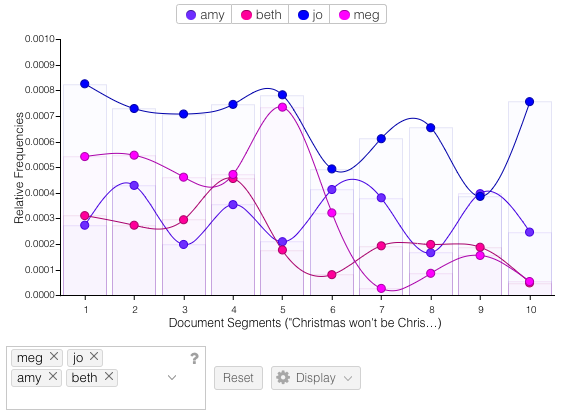
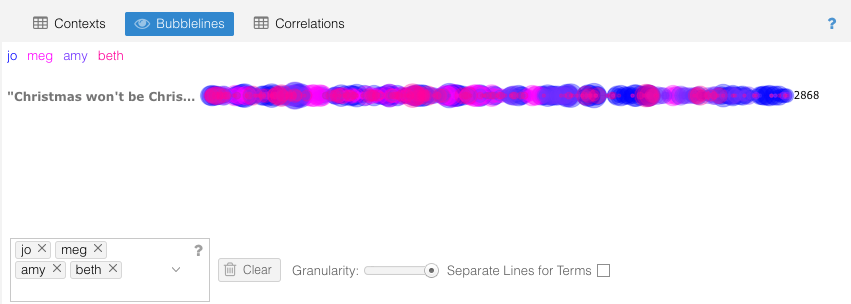
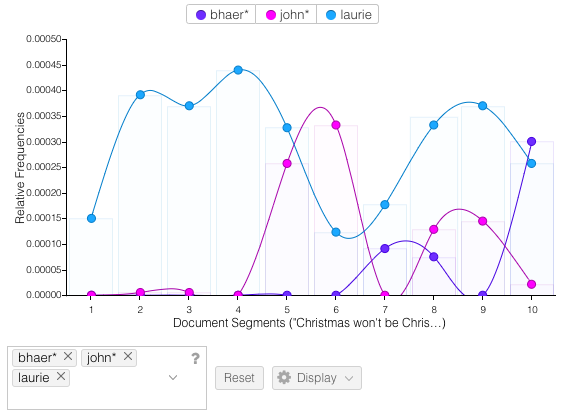
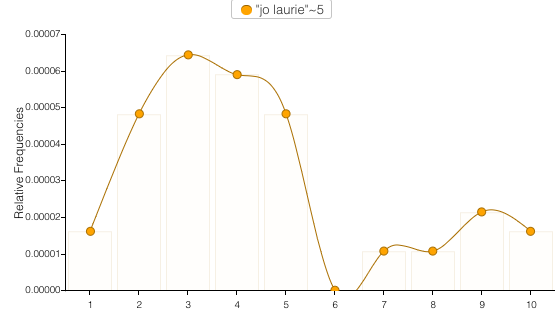
Voyant is easy to use and gives lots of tools to click through and try out. It’s also very visually appealing. I pasted in the text of the full novel and first searched within the Trends and Bubblelines windows to see how often each of the sisters are mentioned throughout the course of the novel. The results are clear to follow and not too surprising (see the number of mentions of Beth and Meg decline after their death and marriage respectively – sorry, spoilers). I did find that 2 of the colors were a little too close in shade, and I didn’t figure out how to change them to see a little more color contrast. Next I wanted to see the equivalent searches for the major male characters of the novel. Laurie was already one of the most common terms, so he popped up in the top 10 drop down to select. But I had to stop and think about how to search for Friedrich Bhaer and John Brooke. I looked up both first and last names to find the most frequent name for each character, and ended up going with “Bhaer” and “John”. Again, clean narratives lines are the end result. I did like being able to reference the content in the Reader window by clicking on one of the points in the Trends chart and seeing it take you right to the start of that content segment. I also found it helpful to hover over an individual word in Reader to see its frequency, and then click to have that term override the Terms window to see that same frequency trend line over the duration of the novel.
Finally I explored the Links feature to see common relationships between words in the text. For obvious reasons I chose to look at the link between Jo and Laurie. It’s really entertaining to watch the word bubbles hover around between the connecting lines. Trends seems to be the default reactor for most of the clicks as immediately clicking on the links line creates a new Trends line there. I accidentally discovered this and had to re-do the previous search to go back.
Voyant really does all the heavy lifting for you, and there’s zero insight into how it operates behind the scenes. For quick, easy to visualize results, Voyant does a great job. While looking specifically at a novel, Voyant was useful for tracing narrative connections. I could see it being some kind of add on to Sparknotes for readers looking to dig deeper into content. But overall I think I was a little disappointed with the tool’s limitations.
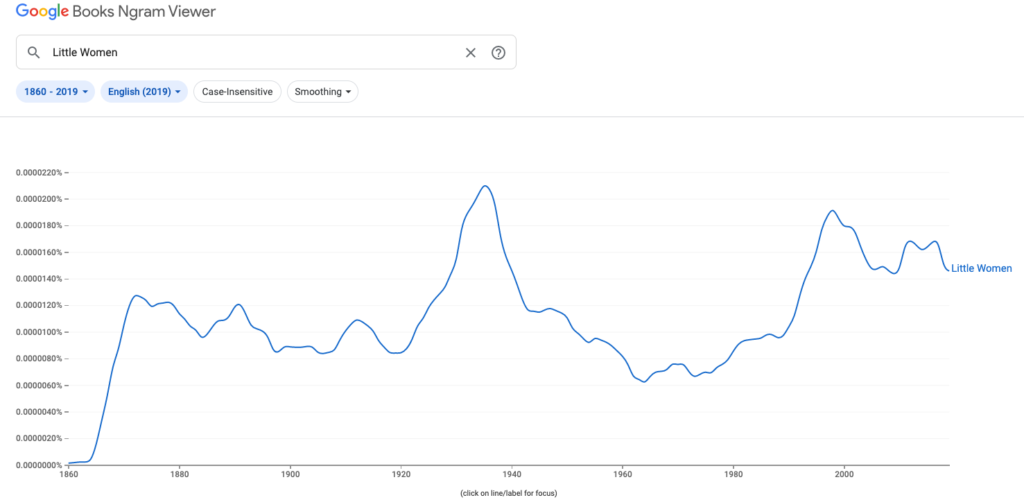
Next I plugged “Little Women” into Google’s Ngram to see frequency trends of the novel title over time. Similar to my work in Voyant, I wasn’t too surprised with the results but had fun using the tool.
The frequency count begins to increase after 1864, continuing up steadily through the novel’s publication in 1868 and peaking at 1872. Then it plateaus and fluctuates through 1920 before dramatically increasing again with the highest peak at 1935. A quick search told me that the story’s first sound film adaptation starring Katharine Hepburn premiered in 1933. For me the best part of using Ngram was playing detective and digging up the reasons behind the frequency increases. A couple other highlights I clued into: the 1994 Academy Award-nominated film adaptation and a major mention in a popular episode of ‘Friends’ in 1997.
Overall I did find the text analysis praxis valuable because I was able to experiment and explore what the tools are capable of. Probably the most important lesson I learned is that projects don’t always turn out the way you expect them to. In a way this is similar to the mapping praxis but instead of the scope limiting me, it was the tools here that put up those constraints. I also think I got in my own way by having really high expectations going into things, thinking I would have a strong hypothesis up front and the tools would help me prove it. We discussed that this area of DH can be challenging despite most initially assuming text mining to be immediately beneficial for projects in the field. And after this praxis, my assumptions have definitely changed.
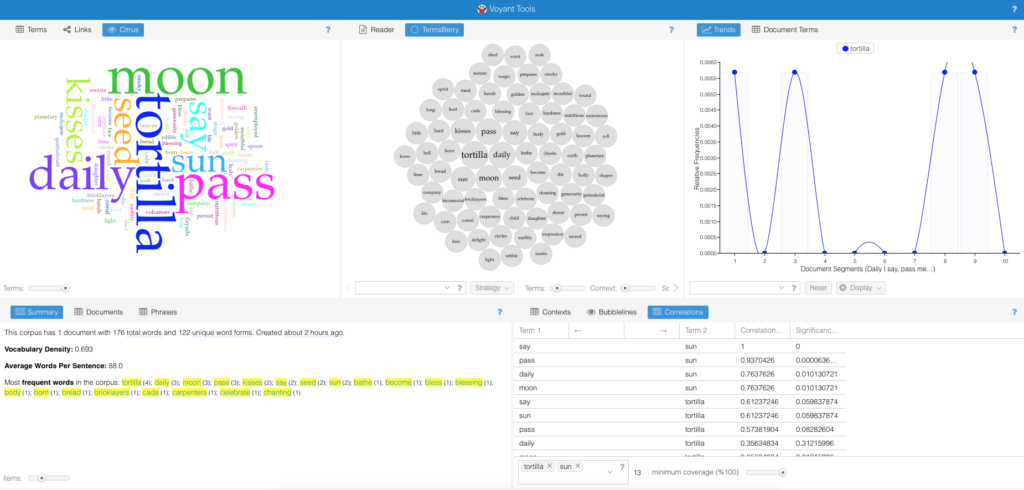
I wanted to test out Voyant’s proficiency when it comes to using a text with multiple languages. To do this, I inserted various texts into the software: English, Spanish, and two texts with a mixture of both. Was Voyant able to 1. distinguish between the two languages and 2. make connections between words and phrases in both English and Spanish?
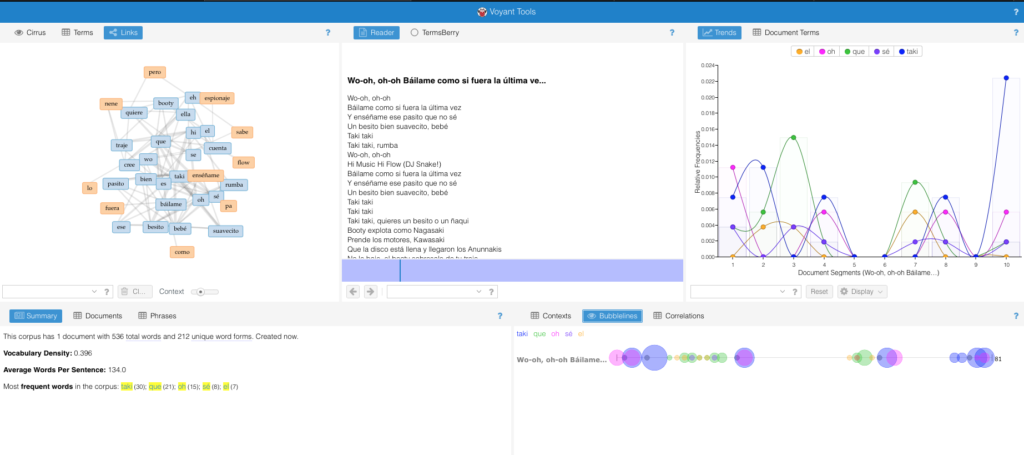
I first used Red Hot Salsa, a bilingual poem edited by Lori Marie Carlson. The text is composed of English and Spanish words adding authenticity to the United States’ Latin American experience. Voyant could not recognize, distinguish, nor take note of the differences in word structure or phrases. The tool objectively calculated the amount words used, the frequency by which they were used, and wherein the text, these words appeared. Another test consisted of a popular bilingual reggaeton song entitled Taki Taki performed by DJ Snake, Ozuna, Cardi B, and Selena Gomez. The system was able to again capture the amount of words and their frequent appearance. Yet, the way it measured the connection was through word proximity and in a song which repeats the same words and phrases, this measurement is not clear.
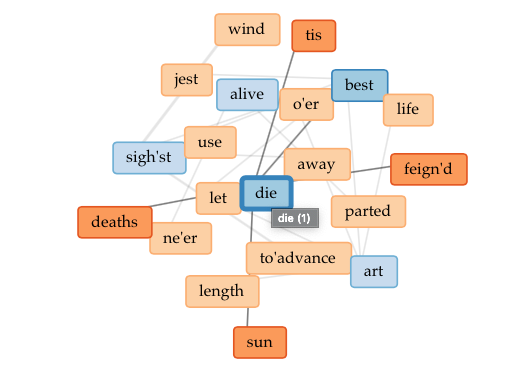
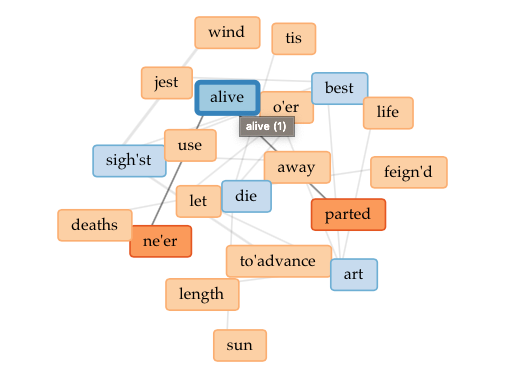
Finally, I decided on an old English text, one of my favorite poems: Sweetest Love, I do not Go by John Donne. Here I looked at the links tool and noticed the connection between the words die, sun, alive, and parted. The tool gave me a visual representation of metaphors inside the poem ( just because we are apart, we won’t die, like the sun, I will come again, alive ). I found the links section the most useful part of Voyant.
While exploring this tool, I recalled Cameron Blevin’s experience with text mining and topic modeling (Digital History’s Perpetual Future Tense). Like most of these digital apparatuses, one must go in with a clear intention prior to the text’s analysis and background. Without this, the quantitative measures will be there, but they will not have much meaning. They will become just Word Soup!
Yesterday I had the pleasure to attend the workshop about Working with HathiTrust data led by Digital Fellow Param Ajmera. In case you missed it, you can find an article about HathiTrust on the Digital Fellows Blog, Tagging the Tower.
HathiTrust is a huge digital library that contains over 17 million volumes, and for this reason it’s particularly good for large-scale text analysis. The advantage of using HathiTrust, as Param showed us, is that you can perform the text analysis on the website of the HathiTrust Research Center – HTRC, a Cloud computing infrastructure that allows us to parse a large amount of text without crashing our computers. And the best part – it’s free and you can create an account with your CUNY login.
Param gave us a live tutorial on how to select the texts we want from HathiTrust and create a collection that we can save and open on HTRC. He created a collection of public papers of American Presidents and used Topic Modeling to find the words that are most commonly used together in these texts. The result was a list of “topics”, groups of words that the algorithm gathered according to how often they appear together. This allowed us to make a comparison between different presidents according to the keywords in their public papers. The experience was very interesting – and with the perfect timing!
The part I enjoyed the most, however, was when Param taught us how to use Bookworm, a tool that creates visualizations of language trends over the entire corpus of HathiTrust. The result is very similar to the Google Ngram Viewer, but Bookworm has one advantage: when you click on a point on the line, you can see a list of the texts where the word appears.
Since topic modeling can take a long time (hours or even days) according to the volume of text you’re working with, I decided to experiment with Bookworm. Here’s my Ngrams:
Being a sci-fi lover, I decided to check the frequency of the words “robot” and “android”. I was initially surprised when I saw that “android”, compared to “robot” had such a low curve. When I checked the texts that were used for the Ngram, I realized that the word “robot” appears in a lot of papers related to engineering, robotics, and information technology, while “android” is a term mostly used in sci-fi. If we look at the curve of “android” alone, we see that the word has a spike in the 1960s. Was it because of Philip Dick? Or Star Trek?
Inspired by the Rocky Horror Picture Show and the TV show “Pose”, I decided to investigate the relative frequency of “transvestite”, “transsexual”, and “transgender” in the HathiTrust corpus. The first two terms sound pretty dated – and rightfully so, while the third one is the most commonly used now. As you can see from the graph, the use of the term “transgender” skyrockets starting in the mid-1980s, beating the other two at the end of the 1990s. Another thing I noticed is that, looking at the texts:
“transvestite” is mostly used to describe a cultural phenomenon (for example in texts about literature, theater, cinema, or fashion)
“transsexual” is used in medical contexts, for example in papers about gender dysphoria
“transgender” is used in a medical context, beating “transsexual” at the end of the 1990s. However, it is also used in and institutional contexts like policies, guidelines, and social justice reforms.
Need help with the Commons?
Email us at [email protected] so we can respond to your questions and requests. Please email from your CUNY email address if possible. Or visit our help site for more information: