
For my text mining assignment, I wanted to see what would happen if I tried separately inputting a book in two different languages. In particular, I wanted to see if Voyant could capture/visualize any translation decisions or “glitches in translation” that may come up when a language is translated from one language to another: Would some words appear more often in one language than another? Would some words not translate clearly? Can translation decisions be captured and understood clearly through a tool like Voyant?
I chose to input PDFs of Frantz Fanon’s 1952 book Peau Noire, Masques Blancs (French translated to English as Black Skins, White Masks), and its 1986 English translation by Charles Lam Markmann. Both versions were downloaded from Monoskop. In both texts, I had the word clouds show just the top 125 words of each text.


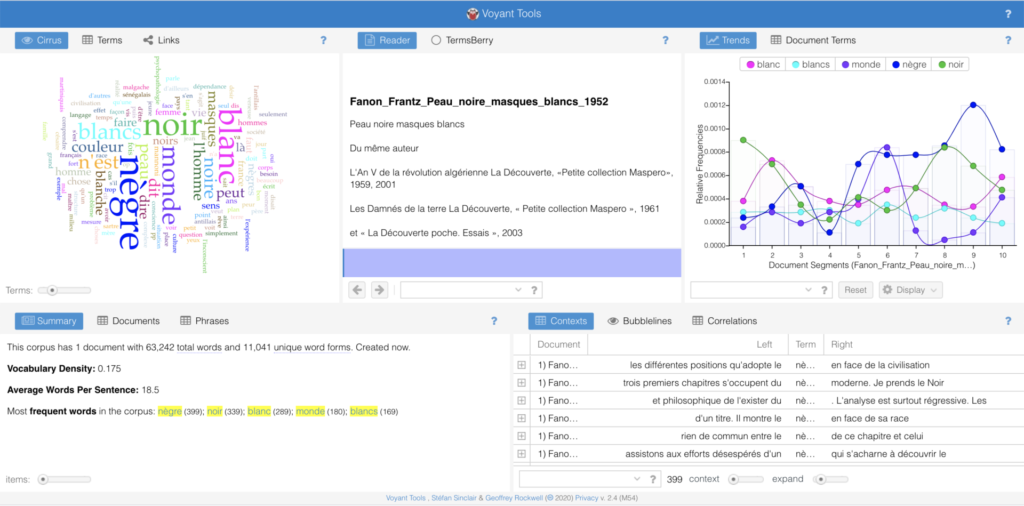
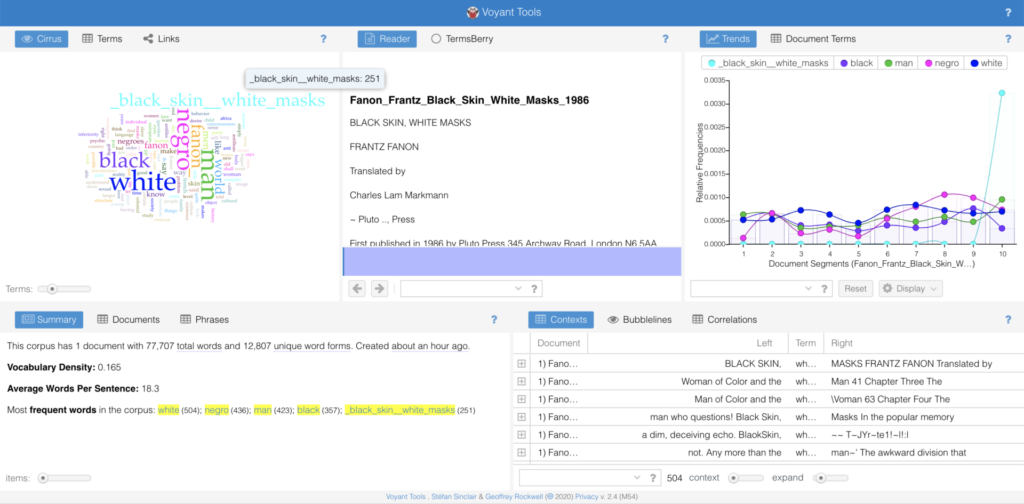
From inputting the two translations into Voyant, the most noticeable was a metadata issue, in that Voyant indexed “_black_skins_white_masks” from the English translated version, causing the “word” to take up a lot of space in the word cloud. Underlines were an issue for a few terms in the English version’s word cloud, as well as inclusions of Fanon’s name as a term. These, I presume, are pieces of metadata hidden throughout the PDF in ways that I cannot trace easily through a simply “ctrl+find” on my Preview application.
In regards to the actual terms, there were clear discrepancies in the frequency of term usage between the English and French versions of the text (at least from the eye of someone who doesn’t know French). To name a few examples: “Noir” was used 339 times, while “black” was used 357 times; “negrè” was used 399 times while “Negro” was used 436 times; “blanc” was used 289 times while “white” was used 504 times; and “l’homme” was used 94 times while “man” was used 423 times. On the one hand, as someone who does not know French, there may be other words in French taht were used in place of, say, “man”, that just “l’homme” and may diagnose the large difference in usage between the two terms.
On the other hand, what is made clear through the word clouds is that specific decisions are made in the act of translation that shows the non-linearity and non-neutrality of the very act. While this is a relatively obvious and drawn-out claim made time and again, it was interesting to see it happen in front of my own eyes. Additionally, its interesting to think about how my understanding of the text may change if/when I learn French and read the text in its original language. This made clear to me why one may prefer different translations to others, and how specific terms may not only better depict a certain claim, but also perhaps historicize and contextualize these claims in ways that particular translations may not be able to communicate.
Overall I found this assignment to be interesting and makes me think about language as a technology/technique in and of itself: The non-neutrality of language, perhaps, as a way in which specific ways of knowing and understanding are brought to the forefront in ways inextricable from power—which is something that Sylvia Wynter has talked about before.

This entry is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International license.
What an interesting idea for your project. Are there other versions (French and/or English)? I wonder what would happen if those got put in. I would suggest that editing is similar to translation, in that they both try to approximate an “essence” of an original text (if there really is such a thing as an original text, assuming authors are self-editing and self-translating their thoughts in the very process of writing).
I’m also curious to know more about the way in which the word cloud is created, as in what rules are being followed in the code. If you put the exact same two texts back into the tool, would you get the exact same word cloud? Or would it mix up the arrangement and colors?